 This is a work-in-progress draft version.
This is a work-in-progress draft version.
Rust Regex
This chapter will cover regular expressions syntax and features of Rust regex — the engine that powers the default regex offered by tools like rg, sd, hck, frawk, etc. From the docs:
Its syntax is similar to Perl-style regular expressions, but lacks a few features like look around and backreferences. In exchange, all searches execute in linear time with respect to the size of the regular expression and search text.
Line Anchors
$ # lines starting with 'pa'
$ printf 'spared no one\npar\nspar\ndare' | rg '^pa'
par
$ # lines ending with 'ar'
$ printf 'spared no one\npar\nspar\ndare' | rg 'ar$'
par
spar
$ # lines containing only 'par'
$ printf 'spared no one\npar\nspar\ndare' | rg '^par$'
par
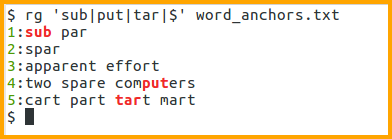
Word Anchors
A word character is any alphabet (irrespective of case), digit and the underscore character. The regex engine implementation is Unicode by default, but consider examples and descriptions as intended for ASCII characters unless otherwise specified.
$ cat word_anchors.txt
sub par
spar
apparent effort
two spare computers
cart part tart mart
$ # match words starting with 'par'
$ rg '\bpar' word_anchors.txt
1:sub par
5:cart part tart mart
$ # match words ending with 'par'
$ rg 'par\b' word_anchors.txt
1:sub par
2:spar
$ # match only whole word 'par'
$ rg '\bpar\b' word_anchors.txt
1:sub par
The word boundary has an opposite anchor too. \B matches wherever \b doesn't match. This duality will be seen with some other escape sequences too.
$ # replace 'par' with 'PAR' if it is surrounded by word characters
$ rg '\Bpar\B' -r 'PAR' word_anchors.txt
3:apPARent effort
4:two sPARe computers
$ # match 'par' but not as start of word
$ rg '\Bpar' word_anchors.txt
2:spar
3:apparent effort
4:two spare computers
$ # match 'par' but not as end of word
$ rg 'par\B' word_anchors.txt
3:apparent effort
4:two spare computers
5:cart part tart mart
$ printf 'copper' | rg '\b' -r ':'
:copper:
$ printf 'copper' | rg '\B' -r ':'
c:o:p:p:e:r
String anchors
\A restricts the match to start of string and \z restricts the match to end of string. This makes a difference if you are working with input data containing more than one line (based on newline character).
$ # -U enables multiline matching
$ # regex multiline modifier m (covered later) is also enabled by default
$ # note that output will contain only matching line(s), not entire input
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U '\Ahi'
hi-hello;top
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U '\Afoo'
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U '^foo'
foo-spot
$ # note that you need to mention \n (if present) for \z
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U 'pot\n\z'
foo-spot
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U 'pot$'
foo-spot
$ printf 'hi-hello;top\nfoo-spot\n' | rg -U 'top$'
hi-hello;top
See my blog post Multiline fixed string search and replace with cli tools for more examples with
-Uoption.
Alternation
Alternation is similar to using multiple -e option, but provides more flexibility when combined with grouping.
$ # match either 'cat' or 'dog', same as: rg -e 'cat' -e 'dog'
$ printf 'I like cats\nI like parrots\nI like dogs' | rg 'cat|dog'
I like cats
I like dogs
$ # match either 'cat' or 'dog' or 'fox' case insensitively
$ echo 'CATs dog bee parrot FoX' | rg -io 'cat|dog|fox'
CAT
dog
FoX
$ echo 'CATs dog bee parrot FoX' | rg -i 'cat|dog|fox' -r 'mammal'
mammals mammal bee parrot mammal
$ # match lines starting with 'a' or a line containing a word ending with 'e'
$ rg '^a|e\b' word_anchors.txt
3:apparent effort
4:two spare computers
A cool use case of alternation is combining line anchors to display entire input file but highlight only required search patterns. This effect can also be achieved using --passthru option instead of using standalone anchors as part of alternation.
There's some tricky situations when using alternation. If it is used to get matching line, there is no ambiguity. However, for matching portion extraction with -o option, it depends on a few factors. Say, you want to get either are or spared — which one should get precedence? The bigger word spared or the substring are inside it or based on something else?
$ # alternative which matches earliest in the input gets precedence
$ # left to right precedence if alternatives match on same index
$ printf 'spared PARTY PaReNt' | rg -io 'par|pare|spare'
spare
PAR
PaR
$ # workaround is to sort alternations based on length, longest first
$ printf 'spared PARTY PaReNt' | rg -io 'spare|pare|par'
spare
PAR
PaRe
$ echo 'best years' | rg 'year|years' -r 'X'
best Xs
$ echo 'best years' | rg 'years|year' -r 'X'
best X
Grouping
Similar to a(b+c)d = abd+acd in maths, you get a(b|c)d = abd|acd in regular expressions.
$ # same as: rg 'reform|rest'
$ printf 'red\nreform\nread\narrest' | rg 're(form|st)'
reform
arrest
$ # same as: '\bpar\b|\bpart\b'
$ # you'll later learn a better technique using quantifiers
$ printf 'sub par\nspare\npart time' | rg '\b(par|part)\b'
sub par
part time
Escaping metacharacters
You have seen a few metacharacters and escape sequences that help to compose a regular expression. To match the metacharacters literally, i.e. to remove their special meaning, prefix those characters with a \ character. To indicate a literal \ character, use \\.
$ # same as: rg -F 'b^2'
$ echo 'a^2 + b^2 - C*3' | rg 'b\^2'
a^2 + b^2 - C*3
$ # cannot use -F here as line anchor is needed
$ printf '(a/b) + c\n3 + (a/b) - c' | rg '^\(a/b\)'
(a/b) + c
The dot meta character
The dot metacharacter serves as a placeholder to match any character except newline.
# extract 'c', followed by any character and then 't'
$ echo 'tac tin cot abc:tuv excite' | rg -o 'c.t'
c t
cot
c:t
cit
# '2', followed by any character and then '3'
$ printf '42\t33\n' | rg '2.3' -r '8'
483
$ # 5 character lines starting with 'c' and ending with 'ty' or 'ly'
$ rg -Nx 'c..(t|l)y' words.txt
catty
coyly
curly
Greedy Quantifiers
The ? metacharacter quantifies a character or group to match 0 or 1 times.
$ # same as: rg '\b(par|part)\b' or rg -w 'par|part'
$ printf 'sub par\nspare\npart time' | rg -w 'part?'
sub par
part time
$ # same as: rg 'part|parrot' -r 'X'
$ echo 'par part parrot parent' | rg 'par(ro)?t' -r 'X'
par X X parent
$ # same as: rg -o 'part|parrot|parent'
$ echo 'par part parrot parent' | rg -o 'par(en|ro)?t'
part
parrot
parent
The * metacharacter quantifies a character or group to match 0 or more times.
$ # extract 'f' followed by zero or more of 'e' followed by 'd'
$ echo 'fd fed fod fe:d feeeeder' | rg -o 'fe*d'
fd
fed
feeeed
$ # replace zero or more of '1' followed by '2' with 'X'
$ echo '3111111111125111142' | rg '1*2' -r 'X'
3X511114X
The + metacharacter quantifies a character or group to match 1 or more times.
$ # extract 'f' followed by at least one of 'e' or 'o' or ':' followed by 'd'
$ echo 'fd fed fod fe:d feeeeder' | rg -o 'f(e|o|:)+d'
fed
fod
fe:d
feeeed
$ # extract one or more of '1' followed by '2'
$ echo '3111111111125111142' | rg -o '1+2'
11111111112
$ # replace one or more of '1' followed by optional '4' and then '2' with 'X'
$ echo '3111111111125111142' | rg '1+4?2' -r 'X'
3X5X
You can specify a range of integer numbers, both bounded and unbounded, using {} metacharacters. There are three ways to use this quantifier as listed below:
| Pattern | Description |
|---|---|
{m,n} | match m to n times |
{m,} | match at least m times |
{n} | match exactly n times |
$ # note that whitespace is allowed within {} but not recommended
$ echo 'abc ac adc abbc xabbbcz bbb bc abbbbbc' | rg -o 'ab{1,4}c'
abc
abbc
abbbc
$ echo 'abc ac adc abbc xabbbcz bbb bc abbbbbc' | rg -o 'ab{3,}c'
abbbc
abbbbbc
$ echo 'abc ac adc abbc xabbbcz bbb bc abbbbbc' | rg -o 'ab{3}c'
abbbc
$ echo 'abc ac adc abbc xabbbcz bbb bc abbbbbc' | rg -o 'ab{0,2}c'
abc
ac
abbc
{}metacharacters have to be escaped to match them literally. However, unlike()metacharacters, escaping{alone is enough.
Next up, how to construct AND conditional using dot metacharacter and quantifiers. To allow matching in any order, you'll have to bring in alternation as well. That is somewhat manageable for 2 or 3 patterns.
$ # match 'Error' followed by zero or more characters followed by 'valid'
$ echo 'Error: not a valid input' | rg -o 'Error.*valid'
Error: not a valid
$ echo 'a cat and a dog' | rg 'cat.*dog|dog.*cat'
a cat and a dog
$ echo 'dog and cat' | rg 'cat.*dog|dog.*cat'
dog and cat
Why are these called greedy quantifiers? If multiple quantities can satisfy the pattern, the longest match wins.
$ # longest match among 'foo' and 'fo' wins here
$ echo 'foot' | rg 'f.?o' -r 'X'
Xt
$ # everything will match here
$ echo 'car bat cod map scat dot abacus' | rg -o '.*'
car bat cod map scat dot abacus
But wait, how did Error.*valid example work? Shouldn't .* consume all the characters after Error? Good question. Depending on the implementation of regular expression engine, longest match will be selected from all valid matches generated with varying number of characters for .* or the engine would backtrack character by character from end of string until the pattern can be satisfied or fails.
$ # extract from start of line to last 'm' in the line
$ echo 'car bat cod map scat dot abacus' | rg -o '.*m'
car bat cod m
$ # extract from first 'c' to last 't' in the line
$ echo 'car bat cod map scat dot abacus' | rg -o 'c.*t'
car bat cod map scat dot
$ # extract from first 'c' to last 'at' in the line
$ echo 'car bat cod map scat dot abacus' | rg -o 'c.*at'
car bat cod map scat
Precedence for quantifiers is left to right, even if it ends in matching less number of characters.
$ # (1|2|3)+ matches as much as possible here, which is '123312'
$ # which results in (12baz)? matching 0 times
$ echo 'foo123312baz' | rg -o 'o(1|2|3)+(12baz)?'
o123312
$ # (1|2|3)+ here matches '1233' to allow overall regex to pass
$ echo 'foo123312baz' | rg -o 'o(1|2|3)+12baz'
o123312baz
Non-greedy quantifiers
As the name implies, these quantifiers will try to match as minimally as possible. Also known as lazy or reluctant quantifiers. Appending a ? to greedy quantifiers makes them non-greedy.
$ # smallest match among 'foo' and 'fo' wins here
$ echo 'foot' | rg 'f.??o' -r 'X'
Xot
$ # overall regex has to be satisfied as minimally as possible
$ echo 'frost' | rg 'f.??o' -r 'X'
Xst
$ echo 'foo 314' | rg -o '\d{2,5}?'
31
$ echo 'that is quite a fabricated tale' | rg -o 't.*?a'
tha
t is quite a
ted ta
Character classes
To create a custom placeholder for limited set of characters, enclose them inside [] metacharacters. It is similar to using single character alternations inside a grouping, but with added flexibility and features. Character classes have their own versions of metacharacters and provide special predefined sets for common use cases. Quantifiers are also applicable to character classes.
$ # same as: rg '(a|e|o)+t'
$ printf 'meeting\ncute\nboat\nsite\nfoot' | rg '[aeo]+t'
meeting
boat
foot
$ echo 'so in to no on' | rg -w '[sot][on]' -r 'X'
X in X no X
$ # lines of length at least 2 and made up of letters 'o' and 'n'
$ rg -Nx '[on]{2,}' words.txt
no
non
noon
on
Character classes have their own metacharacters to help define the sets succinctly. First up, the - metacharacter that helps to define a range of characters instead of having to specify them all individually.
$ # same as: rg -o '[0123456789]+'
$ echo 'Sample123string42with777numbers' | rg -o '[0-9]+'
123
42
777
$ # whole words made up of lowercase alphabets and digits only
$ echo 'coat Bin food tar12 best' | rg -w '[a-z0-9]+' -r 'X'
X Bin X X X
$ # whole words made up of lowercase alphabets, starting with 'p' to 'z'
$ echo 'road i post grip read eat pit' | rg -w '[p-z][a-z]*' -r 'X'
X i X grip X eat X
$ # numbers between 10 to 29
$ echo '23 154 12 26 34' | rg -ow '[12][0-9]'
23
12
26
$ # numbers >= 100 with optional leading zeros
$ echo '0501 035 154 12 26 98234' | rg -ow '0*[1-9][0-9]{2,}'
0501
154
98234
Next metacharacter is ^ which has to specified as the first character of the character class. It negates the set of characters, so all characters other than those specified will be matched.
$ # replace all non-digits
$ echo 'Sample123string42with777numbers' | rg '[^0-9]+' -r 'X'
X123X42X777X
$ # extract last two columns based on a delimiter
$ echo 'foo:123:bar:baz' | rg -o '(:[^:]+){2}$'
:bar:baz
$ # get all sequence of characters surrounded by unique character
$ echo 'I like "mango" and "guava"' | rg -o '"[^"]+"'
"mango"
"guava"
$ # use -v option if it is simpler than negated set: rg -x '[^aeiou]*'
$ printf 'tryst\nfun\nglyph\npity\nwhy' | rg -v '[aeiou]'
tryst
glyph
why
Some commonly used character sets have predefined escape sequences:
\dmatches all digit characters[0-9]\Dmatches all non-digit characters\wmatches all word characters[a-zA-Z0-9_]\Wmatches all non-word characters\smatches all whitespace characters: tab, newline, vertical tab, form feed, carriage return and space\Smatches all non-whitespace characters
$ echo 'Sample123string42with777numbers' | rg '\d+' -r ':'
Sample:string:with:numbers
$ echo 'Sample123string42with777numbers' | rg '\D+' -r ':'
:123:42:777:
$ printf 'lo2ad.;.err_msg--\nant,;.' | rg -o '\w+'
lo2ad
err_msg
ant
$ echo 'tea sea-pit sit-lean bean' | rg -o '[\w\s]+'
tea sea
pit sit
lean bean
A named character set is defined by a name enclosed between [: and :] and has to be used within a character class [], along with any other characters as needed. Using [:^ instead of [: will negate the named character set. See ASCII character classes section for full list.
$ # all alphabets and digits
$ printf 'errMsg\nant2\nm_2\n' | rg -x '[[:alnum:]]+'
errMsg
ant2
$ # other than punctuation characters
$ echo 'pie tie#ink-eat_42;' | rg -o '[[:^punct:]]+'
pie tie
ink
eat
42
Set operations can be applied inside character class between sets. Mostly used to get intersection or difference between two sets, where one/both of them is a character range or predefined character set. To aid in such definitions, you can use [] in nested fashion.
$ # intersection of lowercase alphabets and other than vowel characters
$ # can also use set difference: rg -ow '[a-z--aeiou]+'
$ echo 'tryst glyph pity why' | rg -ow '[a-z&&[^aeiou]]+'
tryst
glyph
why
$ # symmetric difference, [[a-l]~~[g-z]] is same as [a-fm-z]
$ echo 'gets eat top sigh' | rg -ow '[[a-l]~~[g-z]]+'
eat
top
$ # remove all punctuation characters except . ! and ?
$ para='"Hi", there! How *are* you? All fine here.'
$ echo "$para" | rg '[[:punct:]--[.!?]]+' -r ''
Hi there! How are you? All fine here.
Character class metacharacters can be matched literally by specific placement or using \ to escape them.
$ # - should be first or last character within []
$ echo 'ab-cd gh-c 12-423' | rg -ow '[a-z-]{2,}'
ab-cd
gh-c
$ # ] should be first character within []
$ printf 'int a[5]\nfoo\n1+1=2\n' | rg '[]=]'
int a[5]
1+1=2
$ # [ has to be escaped with \
$ echo 'int a[5]' | rg '[x\[.y]'
int a[5]
$ # ^ should be other than first character within []
$ echo 'f*(a^b) - 3*(a+b)/(a-b)' | rg -o 'a[+^]b'
a^b
a+b
Backreferences
The grouping metacharacters () are also known as capture groups. Similar to variables in programming languages, the string captured by () can be referred later using backreference $N where N is the capture group you want. Leftmost ( in the regular expression is $1, next one is $2 and so on. By default, $0 will give entire matched portion. Use ${N} to avoid ambiguity between backreference and other characters.
# remove square brackets that surround digit characters
$ echo '[52] apples [and] [31] mangoes' | rg '\[(\d+)]' -r '$1'
52 apples [and] 31 mangoes
# add something around the matched strings
$ echo '52 apples and 31 mangoes' | rg '\d+' -r '(${0}4)'
(524) apples and (314) mangoes
# replace __ with _ and delete _ if it is alone
$ echo '_foo_ __123__ _baz_' | rg '(_)?_' -r '$1'
foo _123_ baz
# swap words that are separated by a comma
$ echo 'good,bad 42,24' | rg '(\w+),(\w+)' -r '$2,$1'
bad,good 24,42
You can use a non-capturing group to avoid keeping a track of groups not needed for backreferencing. The syntax is (?:pattern) to define a non-capturing group.
$ # with normal grouping, need to keep track of all the groups
$ echo '1,2,3,4,5,6,7' | rg '^(([^,]+,){3})([^,]+)' -r '$1($3)'
1,2,3,(4),5,6,7
$ # using non-capturing groups, only relevant groups have to be tracked
$ echo '1,2,3,4,5,6,7' | rg '^((?:[^,]+,){3})([^,]+)' -r '$1($2)'
1,2,3,(4),5,6,7
Regular expressions can get cryptic and difficult to maintain, even for seasoned programmers. There are a few constructs to help add clarity. One such is named capture groups and using that name for backreferencing instead of plain numbers.
$ echo 'a,b 42,24' | rg '(?P<fw>\w+),(?P<sw>\w+)' -r '$sw,$fw'
b,a 24,42
$ row='today,2008-24-03,food,2012-12-08,nice,5632'
$ echo "$row" | rg '(?P<dd>-\d{2})(?P<mm>-\d{2})' -r '$mm$dd'
today,2008-03-24,food,2012-08-12,nice,5632
Using backreference along with -o and -r options will allow to extract matches that should also satisfy some surrounding conditions. This is a workaround for some of the cases where lookarounds are needed.
$ # extract digits that follow =
$ echo 'foo=42, bar=314, baz:512' | rg -o '=(\d+)' -r '$1'
42
314
$ # extract digits only if it is preceded by - and followed by ; or :
$ echo '42 foo-5, baz3; x-83, y-20: f12' | rg -o '\-(\d+)[:;]' -r '$1'
20
$ # extract 3rd occurrence of 'cat' followed by optional lowercase letters
$ s='scatter cat cater scat concatenate abdicate'
$ echo "$s" | rg -o '^(?:.*?cat.*?){2}(cat[a-z]*)' -r '$1'
cater
As $ is special in replacement section, you'll need $$ to represent it literally.
$ echo 'a b a' | rg 'a' -r '$${a}'
${a} b ${a}
Modifiers
Modifiers are like command line options to change the default behavior of the pattern. The -i option is an example for modifier. However, unlike -i, these modifiers can be applied selectively to portions of a pattern. In regular expression parlance, modifiers are also known as flags.
| Modifier | Description |
|---|---|
i | case sensitivity |
m | multiline for line anchors |
s | matching newline with . metacharacter |
x | readable pattern with whitespace and comments |
u | unicode |
To apply modifiers to selectively, specify them inside a special grouping syntax. This will override the modifiers applied to entire pattern, if any. The syntax variations are:
(?modifiers:pattern)will apply modifiers only for this portion(?-modifiers:pattern)will negate modifiers only for this portion(?modifiers-modifiers:pattern)will apply and negate particular modifiers only for this portion(?modifiers)when pattern is not given, modifiers (including negation) will be applied from this point onwards
$ # same as: rg -i 'cat' -r 'X'
$ echo 'Cat cOnCaT scatter cut' | rg '(?i)cat' -r 'X'
X cOnX sXter cut
$ # override -i option
$ printf 'Cat\ncOnCaT\nscatter\ncut' | rg -i '(?-i)cat'
scatter
$ # same as: rg -i '(?-i:Cat)[a-z]*\b' -r 'X' or rg 'Cat(?i)[a-z]*\b' -r 'X'
$ echo 'Cat SCatTeR CATER cAts' | rg 'Cat(?i:[a-z]*)\b' -r 'X'
X SX CATER cAts
$ # allow . metacharacter to match newline character as well
$ printf 'Hi there\nHave a Nice Day' | rg -U '(?s)the.*ice' -r ''
Hi Day
$ # multiple modifiers can be used together
$ printf 'Hi there\nHave a Nice Day' | rg -Uo '(?is)the.*day'
there
Have a Nice Day
Here's an example with both string and line anchors:
$ cat script
#!/usr/bin/python3
import math
print(math.pi)
$ # whole word 'python3' in 1st line and a line starting with 'import'
$ # note the use of string anchor and that m modifier is enabled by default
$ rg -Ul '\A.*\bpython3\b(?s).*^import' script
script
$ # no output if m is disabled
$ rg -Ul '(?-m)\A.*\bpython3\b(?s).*^import' script
The x modifier allows to use literal unescaped whitespaces for readability purposes and add comments after unescaped # character. This modifier has limited usage for cli applications as multiline pattern cannot be specified.
$ echo 'fox,cat,dog,parrot' | rg -o '(?x) ( ,[^,]+ ){2}$ #last 2 columns'
,dog,parrot
$ # need to escape whitespaces or use them inside [] to match literally
$ echo 'a cat and a dog' | rg '(?x)t a'
$ echo 'a cat and a dog' | rg '(?x)t\ a'
a cat and a dog
$ echo 'foo a#b 123' | rg -o '(?x)a#.'
a
$ echo 'foo a#b 123' | rg -o '(?x)a\#.'
a#b
Unicode
Similar to named character classes and escape sequences, the \p{} construct offers various predefined sets to work with Unicode strings. See regular-expressions: Unicode for details. See also -E option regarding other encoding support.
$ # all consecutive letters
$ # note that {} is not necessary here as L is single character
$ echo 'fox:αλεπού,eagle:αετός' | rg '\p{L}+' -r '($0)'
(fox):(αλεπού),(eagle):(αετός)
$ # extract all consecutive Greek letters
$ echo 'fox:αλεπού,eagle:αετός' | rg -o '\p{Greek}+'
αλεπού
αετός
$ # \d, \w, etc are unicode aware
$ echo 'φοο12,βτ_4,foo' | rg '\w+' -r '[$0]'
[φοο12],[βτ_4],[foo]
$ # can be changed by using u modifier
$ echo 'φοο12,βτ_4,foo' | rg '(?-u)\w+' -r '[$0]'
φοο[12],βτ[_4],[foo]
$ # extract all characters other than letters, \PL can also be used
$ echo 'φοο12,βτ_4,foo' | rg -o '\P{L}+'
12,
_4,
Characters can be specified using hexadecimal \x{} codepoints as well.
$ # {} are optional if only two hex characters are needed
$ echo 'a cat and a dog' | rg 't\x20a'
a cat and a dog
$ echo 'fox:αλεπού,eagle:αετός' | rg -o '[\x61-\x7a]+'
fox
eagle
$ echo 'fox:αλεπού,eagle:αετός' | rg -o '[\x{3b1}-\x{3bb}]+'
αλε
αε