Frequently used options
This chapter will cover many of the options provided by GNU grep. Regular expressions will be covered later, so the examples in this chapter will only use literal strings as search patterns. Literal (fixed string) matching refers to exact string comparison, so no special meaning is assigned for any of the search characters.
The example_files directory has all the files used in the examples.
Basic string search
By default, grep will print all the input lines that match the given search patterns. The newline character \n is the line separator by default. This section will show you how to filter lines matching a given search string using grep. Consider this sample input file:
$ cat ip.txt
it is a warm and cozy day
listen to what I say
go play in the park
come back before the sky turns dark
There are so many delights to cherish
Apple, Banana and Cherry
Bread, Butter and Jelly
Try them all before you perish
To filter desired lines, invoke the grep command, pass the search string and then specify one or more filenames that have to be searched. As a good practice, always use single quotes around the search string. Examples requiring shell interpretation will be discussed later.
$ grep 'play' ip.txt
go play in the park
$ grep 'y t' ip.txt
come back before the sky turns dark
Try them all before you perish
grep will perform the search on stdin data if there are no file arguments or if - is used as a filename.
$ printf 'apple\nbanana\nmango\nfig\n' | grep 'an'
banana
mango
$ printf 'apple\nbanana\nmango\nfig\n' | grep 'an' -
banana
mango
Here's an example where grep reads user written stdin data and the filtered output is redirected to a file.
# press Ctrl+d after the line containing 'histogram'
$ grep 'is' > op.txt
hi there
this is a sample line
have a nice day
histogram
$ cat op.txt
this is a sample line
histogram
$ rm op.txt
If your input file has
\r\n(carriage return and newline characters) as the line ending, convert the input file to Unix-style before processing. See stackoverflow: Why does my tool output overwrite itself and how do I fix it? for a detailed discussion and mitigation methods.# Unix style $ printf '42\n' | file - /dev/stdin: ASCII text # DOS style $ printf '42\r\n' | file - /dev/stdin: ASCII text, with CRLF line terminators
Fixed string search
The search string (pattern) is treated as a Basic Regular Expression (BRE) by default. But regular expressions is a topic for the next chapter. For now, use the -F option to indicate that the patterns should be matched literally.
# oops, why did it not match?
$ echo 'int a[5]' | grep 'a[5]'
# where did that error come from??
$ echo 'int a[5]' | grep 'a['
grep: Invalid regular expression
# what is going on???
$ echo 'int a[5]' | grep 'a[5'
grep: Unmatched [, [^, [:, [., or [=
# use the -F option to match strings literally
$ echo 'int a[5]' | grep -F 'a[5]'
int a[5]
GNU grepwill try a literal search even if the-Foption isn't used.
Case insensitive search
Sometimes, you don't know if a log file contains search terms, such as error, Error, or ERROR. In such cases, you can use the -i option to ignore case.
$ grep -i 'the' ip.txt
go play in the park
come back before the sky turns dark
There are so many delights to cherish
Try them all before you perish
$ printf 'Cat\ncOnCaT\ncut\n' | grep -i 'cat'
Cat
cOnCaT
Invert matching lines
Use the -v option to get lines other than those matching the search term.
$ seq 4 | grep -v '3'
1
2
4
$ printf 'goal\nrate\neat\npit' | grep -v 'at'
goal
pit
-l -L,-h -H, negative logic in regular expressions and so on in the examples to follow.
Line number and count
The -n option will prefix line numbers to matching results, using a colon character as the separator. This is useful to quickly locate matching lines for further processing.
$ grep -n 'to' ip.txt
2:listen to what I say
6:There are so many delights to cherish
$ printf 'great\nneat\nuser' | grep -n 'eat'
1:great
2:neat
Having to count the total number of matching lines comes up often. Somehow piping grep output to the wc command is prevalent instead of simply using the -c option.
# number of lines matching the pattern
$ grep -c 'is' ip.txt
4
# number of lines NOT matching the pattern
$ printf 'goal\nrate\neat\npit' | grep -vc 'g'
3
When multiple input files are passed, the count is displayed for each file separately. Use cat if you need a combined count.
# here - represents the stdin data
$ printf 'this\nis\ncool\n' | grep -c 'is' ip.txt -
ip.txt:4
(standard input):2
# useful application of the cat command
$ cat <(printf 'this\nis\ncool\n') ip.txt | grep -c 'is'
6
-coption is the total number of lines matching the given patterns, not the total number of matches. Use the-ooption, and pipe the output towc -lto count every occurrence (example will be shown later).
Limiting output lines
Sometimes, there are too many results, in which case you could pipe the output to a pager tool like less. Or use the -m option to limit how many matching lines should be displayed for each input file. grep will stop processing an input file as soon as the condition specified by -m is satisfied. Note that just like the -c option, -m works by line count and not based on the total number of matches.
$ grep -m2 'is' ip.txt
it is a warm and cozy day
listen to what I say
$ seq 1000 | grep -m4 '2'
2
12
20
21
Multiple search strings
The -e option can be used to specify multiple search strings from the command line. This is similar to conditional OR boolean logic.
# search for 'what' or 'But'
$ grep -e 'what' -e 'But' ip.txt
listen to what I say
Bread, Butter and Jelly
If you have a huge list of strings to search, save them in a file, one search string per line. Make sure there are no empty lines. Then use the -f option to specify a file as the source of search strings. You can use this option multiple times and also add more patterns from the command line using the -e option. Also, add the -F option when searching for literal matches. It is easy to miss regular expression metacharacters in a big list of terms.
$ cat search.txt
say
you
$ grep -Ff search.txt ip.txt
listen to what I say
Try them all before you perish
# example with both -f and -e options
$ grep -Ff search.txt -e 'it' -e 'are' ip.txt
it is a warm and cozy day
listen to what I say
There are so many delights to cherish
Try them all before you perish
To find lines matching more than one search term, you'd need to either resort to using regular expressions (covered later) or workaround by using shell pipes. This is similar to conditional AND boolean logic.
# match lines containing both 'is' and 'to' in any order
# same as: grep 'to' ip.txt | grep 'is'
$ grep 'is' ip.txt | grep 'to'
listen to what I say
There are so many delights to cherish
Get filename instead of matching lines
Often, you just want a list of filenames that match the search patterns. The output might get saved for future reference or passed to another command like sed, awk, perl, sort, etc for further processing. Some of these commands can handle search by themselves, but grep is a fast and specialized tool for searching and using shell pipes can improve performance if parallel processing is available. Similar to the -m option, grep will stop processing the input file as soon as the given condition is satisfied.
-lwill list files matching the pattern-Lwill list files NOT matching the pattern
Here are some examples:
# list filename if it contains 'are'
$ grep -l 'are' ip.txt search.txt
ip.txt
# no output because no match was found
$ grep -l 'xyz' ip.txt search.txt
# list filename if it contains 'say'
$ grep -l 'say' ip.txt search.txt
ip.txt
search.txt
# list filename if it does NOT contain 'xyz'
$ grep -L 'xyz' ip.txt search.txt
ip.txt
search.txt
# list filename if it does NOT contain 'are'
$ grep -L 'are' ip.txt search.txt
search.txt
Filename prefix for matching lines
If there are multiple input files, grep will automatically prefix the filename when displaying the matching lines. You can also control whether or not to add the prefix using the following options:
-hoption will prevent filename prefix in the output (default for single input file)-Hoption will always show filename prefix (default for multiple input files)
# -h is on by default for single input file
$ grep 'say' ip.txt
listen to what I say
# use -h to suppress filename prefix for multiple input files
$ printf 'say\nyou\n' | grep -h 'say' - ip.txt
say
listen to what I say
# -H is on by default for multiple input files
$ printf 'say\nyou\n' | grep 'say' - ip.txt
(standard input):say
ip.txt:listen to what I say
# use -H to always show filename prefix
# instead of -H, you can also provide /dev/null as an additional input file
$ grep -H 'say' ip.txt
ip.txt:listen to what I say
Quickfix
The vim editor has a quickfix option -q that makes it easy to edit the matching lines from grep's output. Make sure that the output has both line numbers and filename prefixes.
# -H ensures filename prefix and -n provides line numbers
$ grep -Hn 'say' ip.txt search.txt
ip.txt:2:listen to what I say
search.txt:1:say
# use :cn and :cp to navigate to the next/previous occurrences
# command-line area at the bottom will show the number of matches and filenames
# you can also save the grep output and pass that filename instead of <()
$ vim -q <(grep -Hn 'say' ip.txt search.txt)
Colored output
When working from the terminal, having the --color option enabled makes it easier to spot the matching portions in the output. Especially useful when you are experimenting to find the correct regular expression. Modern terminals will usually have color support, see unix.stackexchange: How to check if bash can print colors? for details.
The --color (or --colour) option will highlight matching patterns, line numbers, filenames, etc. There are three different settings:
autowill result in color highlighting when results are displayed on terminal, but not when the output is redirected to another command, file, etc. This is the default settingalwayswill result in color highlighting when results are displayed on terminal as well as when the output is redirected to another command, file, etcneverexplicitly disables color highlighting
Here are couple of examples with the --color option enabled (default is auto).

It is typical to alias both the ls and grep commands to include --color=auto.
# aliases are usually saved in ~/.bashrc or ~/.bash_aliases
$ alias ls='ls --color=auto'
$ alias grep='grep --color=auto'
Using --color=always is handy if you want to retain color information even when the output is redirected. For example, piping the results to the less command.
$ grep --color=always -i 'the' ip.txt | less -R
The below image will help you understand the difference between the auto and always features. In the first case, is gets highlighted even after piping, while in the second case is loses the color information. In practice, always is rarely used as it provides extra information to matching lines, which could cause undesirable results when processed.

Match whole word
A word character is any alphabet (irrespective of case), digit and the underscore character. You might wonder why there are digits and underscores as well, why not only alphabets? This comes from variable and function naming conventions — typically alphabets, digits and underscores are allowed. So, the definition is more programming oriented than natural language. The -w option will ensure that given patterns are not surrounded by other word characters. For example, this helps to distinguish par from spar, park, apart, par2, _par, etc.
# this matches 'par' anywhere in the line
$ printf 'par value\nheir apparent\n' | grep 'par'
par value
heir apparent
# this matches 'par' only as a whole word
$ printf 'par value\nheir apparent\n' | grep -w 'par'
par value
-woption behaves a bit differently than word boundaries in regular expressions. See the Word boundary differences section for details.
Match whole line
Another useful option is -x, which will display a line only if the entire line satisfies the given pattern.
# this matches 'my book' anywhere in the line
$ printf 'see my book list\nmy book\n' | grep 'my book'
see my book list
my book
# this matches 'my book' only as a whole line
$ printf 'see my book list\nmy book\n' | grep -x 'my book'
my book
$ grep 'say' ip.txt search.txt
ip.txt:listen to what I say
search.txt:say
$ grep -x 'say' ip.txt search.txt
search.txt:say
# count empty lines, won't work for files with DOS style line endings
$ grep -cx '' ip.txt
1
Comparing lines between files
The -f and -x options can be combined to get common lines between two files or the difference when -v is used as well. If you want to match the lines literally, it is advised to use the -F option as well, because you might not know if there are regular expression metacharacters present in the input files or not.
$ printf 'teal\nlight blue\nbrown\nyellow\n' > colors_1
$ printf 'blue\nblack\ndark green\nyellow\n' > colors_2
# common lines between two files
$ grep -Fxf colors_1 colors_2
yellow
# lines present in colors_2 but not in colors_1
$ grep -Fvxf colors_1 colors_2
blue
black
dark green
# lines present in colors_1 but not in colors_2
$ grep -Fvxf colors_2 colors_1
teal
light blue
brown
See also stackoverflow: Fastest way to find lines of a text file from another larger text file — go through all the answers.
Extract only the matching portions
If the total number of matches is required, use the -o option to display only the matching portions (one per line), and then use wc to count them. This option is more commonly used with regular expressions.
$ grep -oi 'the' ip.txt
the
the
The
the
# -c only gives the count of matching lines
$ grep -c 'an' ip.txt
4
# use -o to get each match on a separate line
$ grep -o 'an' ip.txt | wc -l
6
Summary
In my initial years of CLI usage as a VLSI engineer, I knew only some of the options listed in this chapter. Didn't even know about the --color option. I've come across comments about not knowing the -c option in online forums. These are some of the reasons why I'd advise going through the list of all the options if you use a command frequently. Bonus points for maintaining a cheatsheet of example usage for future reference, passing on to your colleagues, etc.
Interactive exercises
I wrote a TUI app to help you solve some of the exercises from this book interactively. See GrepExercises repo for installation steps and app_guide.md for instructions on using this app.
Here's a sample screenshot:
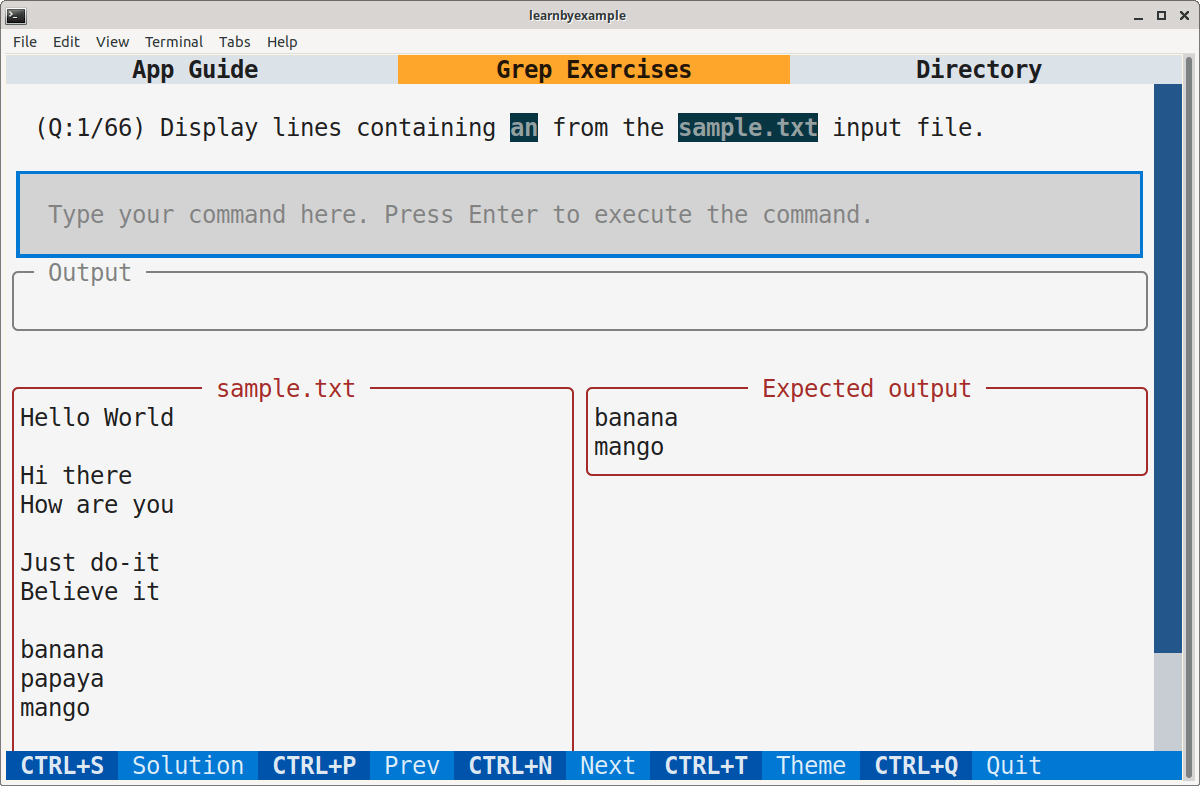
Exercises
1) Display lines containing an from the sample.txt input file.
##### add your solution here
banana
mango
2) Display lines containing do as a whole word from the sample.txt input file.
##### add your solution here
Just do-it
3) Display lines from sample.txt that satisfy both of these conditions:
hematched irrespective of case- either
WorldorHimatched case sensitively
##### add your solution here
Hello World
Hi there
4) Display lines from code.txt containing fruit[0] literally.
##### add your solution here
fruit[0] = 'apple'
5) Display only the first two matching lines containing t from the sample.txt input file.
##### add your solution here
Hi there
Just do-it
6) Display only the first three matching lines that do not contain he from the sample.txt input file.
##### add your solution here
Hello World
How are you
7) Display lines from sample.txt that contain do along with line number prefix.
##### add your solution here
6:Just do-it
13:Much ado about nothing
8) For the input file sample.txt, count the number of times the string he is present, irrespective of case.
##### add your solution here
5
9) For the input file sample.txt, count the number of empty lines.
##### add your solution here
4
10) For the input files sample.txt and code.txt, display matching lines based on the search terms (one per line) present in the terms.txt file. Results should be prefixed with the corresponding input filename.
$ cat terms.txt
are
not
go
fruit[0]
##### add your solution here
sample.txt:How are you
sample.txt:mango
sample.txt:Much ado about nothing
sample.txt:Adios amigo
code.txt:fruit[0] = 'apple'
11) For the input file sample.txt, display lines containing amigo prefixed by the input filename as well as the line number.
##### add your solution here
sample.txt:15:Adios amigo
12) For the input files sample.txt and code.txt, display only the filename if it contains apple.
##### add your solution here
code.txt
13) For the input files sample.txt and code.txt, display only whole matching lines based on the search terms (one per line) present in the lines.txt file. Results should be prefixed with the corresponding input filename as well as the line number.
$ cat lines.txt
banana
fruit = []
##### add your solution here
sample.txt:9:banana
code.txt:1:fruit = []
14) For the input files sample.txt and code.txt, count the number of lines that do not match any of the search terms (one per line) present in the terms.txt file.
##### add your solution here
sample.txt:11
code.txt:3
15) Count the total number of lines containing banana in the input files sample.txt and code.txt.
##### add your solution here
2
16) Which two conditions are necessary for the output of the grep command to be suitable for the vim -q quickfix mode?
17) What's the default setting for the --color option? Give an example where the always setting would be useful.
18) The command shown below tries to get the number of empty lines, but apparently shows the wrong result, why?
$ grep -cx '' dos.txt
0