Escaping metacharacters
You have seen a few metacharacters and escape sequences that help compose a RegExp literal. There's also the / character used as a delimiter for RegExp objects. This chapter will show how to remove the special meaning of such constructs. Also, you'll learn how to take care of these special characters when you are building a RegExp literal from normal strings.
Escaping with backslash
To match the metacharacters literally, i.e. to remove their special meaning, prefix those characters with a \ (backslash) character. To indicate a literal \ character, use \\.
// even though ^ is not being used as an anchor, it won't be matched literally
> /b^2/.test('a^2 + b^2 - C*3')
< false
// escaping will work
> /b\^2/.test('a^2 + b^2 - C*3')
< true
// match ( or ) literally
> '(a*b) + c'.replace(/\(|\)/g, '')
< 'a*b + c'
> '\\learn\\by\\example'.replace(/\\/g, '/')
< '/learn/by/example'
Dynamically escaping metacharacters
When you are defining the regexp yourself, you can manually escape the metacharacters where needed. However, if you have strings obtained from elsewhere and need to match the contents literally, you'll have to somehow escape all the metacharacters while constructing the regexp. The solution of course is to use regular expressions! Usually, the programming language itself would provide a builtin method for such cases. JavaScript doesn't, but MDN: Regular Expressions Guide has it covered in the form of a function as shown below.
> function escapeRegExp(string) {
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&')
}
There are many things in the above regexp that you haven't learnt yet. They'll be discussed in the coming chapters. For now, it is enough to know that this function will automatically escape all the metacharacters. Examples are shown below.
// sample input on which the regexp will be applied
> let eqn = 'f*(a^b) - 3*(a^b)'
// sample string obtained from elsewhere which needs to be matched literally
> const usr_str = '(a^b)'
// case 1: replace all matches
// escaping metacharacters using the 'escapeRegExp' function
> const pat = new RegExp(escapeRegExp(usr_str), 'g')
> pat
< /\(a\^b\)/g
> eqn.replace(pat, 'c')
< 'f*c - 3*c'
// case 2: replace only at the end of the input string
> eqn.replace(new RegExp(escapeRegExp(usr_str) + '$'), 'c')
"f*(a^b) - 3*c"
Note that the
/delimiter character isn't escaped in the above function. You can use[.*+?^${}()|[\]\\\/]to escape the delimiter as well.
Dynamically building alternation
Examples in the previous chapter showed cases where a single regexp can contain multiple patterns combined using the | metacharacter. Often, you have an array of strings and the requirement is to match any of the elements literally. To do so, you need to escape all the metacharacters before combining the strings with the | metacharacter. The function shown below uses the escapeRegExp() function introduced in the previous section.
> function unionRegExp(arr) {
return arr.map(w => escapeRegExp(w)).join('|')
}
And here are some examples with the unionRegExp() function used to construct the required regexp.
// here, the order of alternation wouldn't matter
// and assume that other regexp features aren't needed
> let w1 = ['c^t', 'dog$', 'f|x']
> const p1 = new RegExp(unionRegExp(w1), 'g')
> p1
< /c\^t|dog\$|f\|x/g
> 'c^t dog$ bee parrot f|x'.replace(p1, 'mammal')
< 'mammal mammal bee parrot mammal'
// here, alternation precedence rules needs to be applied first
// and assume that the terms have to be matched as whole words
> let w2 = ['hand', 'handy', 'handful']
// sort by the string length, longest first
> w2.sort((a, b) => b.length - a.length)
< ['handful', 'handy', 'hand']
> const p2 = new RegExp(`\\b(${unionRegExp(w2)})\\b`, 'g')
> p2
< /\b(handful|handy|hand)\b/g
// note that 'hands' and 'handed' aren't replaced
> 'handful handed handy hands hand'.replace(p2, 'X')
< 'X handed X hands X'
source and flags properties
If you need the contents of a RegExp object, you can use the source and flags properties to get the pattern string and flags respectively. These methods will help you to build a RegExp object using the contents of another RegExp object.
> const p3 = /\bpar\b/
> const p4 = new RegExp(p3.source + '|cat', 'g')
> p4
< /\bpar\b|cat/g
> console.log(p4.source)
< \bpar\b|cat
> p4.flags
< 'g'
> 'cater cat concatenate par spare'.replace(p4, 'X')
< 'Xer X conXenate X spare'
Escaping the delimiter
Another character to keep track for escaping is the delimiter used to define the RegExp literal. Or depending upon the pattern, you can use the new RegExp constructor to avoid escaping.
> let path = '/home/joe/report/sales/ip.txt'
// this is known as 'leaning toothpick syndrome'
> path.replace(/^\/home\/joe\//, '~/')
< '~/report/sales/ip.txt'
// using 'new RegExp' improves readability and can reduce typos
> path.replace(new RegExp(`^/home/joe/`), '~/')
< '~/report/sales/ip.txt'
Escape sequences
Certain characters like tab and newline can be expressed using escape sequences as \t and \n respectively. These are similar to how they are treated in normal string literals. However, \b is for word boundaries as seen earlier, whereas it stands for the backspace character in normal string literals.
Additionally, there are several sequences that are specific to regexps. The full list is mentioned in the Using special characters section of MDN documentation. These are \b \B \cX \d \D \f \k<name> \n \p \P \r \s \S \t \uhhhh \u{hhhh} \v \w \W \xhh \0. Here are some examples:
> 'a\tb\tc'.replace(/\t/g, ':')
< 'a:b:c'
> '1\n2\n3'.replace(/\n/g, ' ')
< '1 2 3'
// use \\ instead of \ when constructing regexp from string literals
// when you need to represent a single backslash character literally
> new RegExp('123\tabc')
< /123 abc/
> new RegExp('123\\tabc')
< /123\tabc/
Here's a console screenshot of another example.
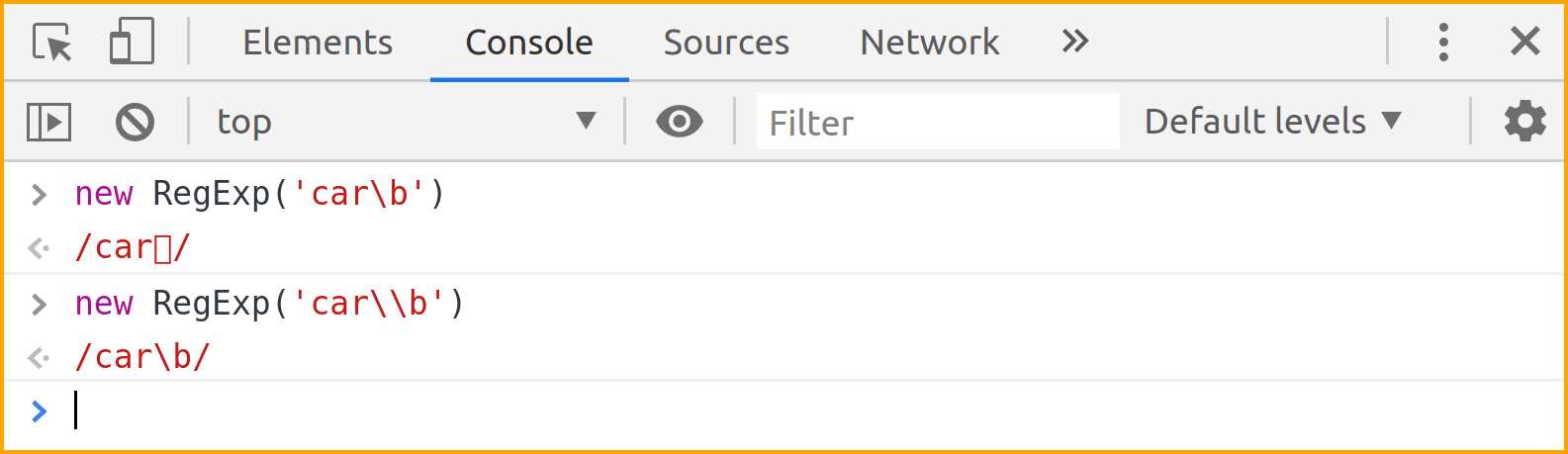
If an escape sequence is not defined, it will be treated as the character it escapes.
// here \e is treated as e
> /\e/.test('hello')
< true
You can also represent a character using hexadecimal escape of the format \xhh where hh are exactly two hexadecimal characters. If you represent a metacharacter using escapes, it will be treated literally instead of its metacharacter feature. The Codepoints section will discuss escapes for unicode characters.
// \x20 is the space character
> 'h e l l o'.replace(/\x20/g, '')
< 'hello'
// \x7c is the '|' character
// but it won't be treated as the alternation metacharacter
> '12|30'.replace(/2\x7c3/g, '5')
< '150'
> '12|30'.replace(/2|3/g, '5')
< '15|50'
Cheatsheet and Summary
| Note | Description |
|---|---|
\ | prefix metacharacters with \ to match them literally |
\\ | to match \ literally |
source | property to convert a RegExp object to a string |
| helps to insert a RegExp inside another RegExp | |
flags | property to get flags of a RegExp object |
RegExp(`pat`) | helps to avoid or reduce escaping the / delimiter character |
| Alternation precedence | tie-breaker is left-to-right if matches have the same starting location |
| robust solution: sort the alternations based on length, longest first | |
\t | escape sequences like those supported in string literals |
\b | word boundary in regexps but backspace in string literals |
\e | undefined escapes will match the character it escapes |
\xhh | represent a character using hexadecimal values |
\x7c | matches | literally |
Exercises
1) Transform the given input strings to the expected output using the same logic on both strings.
> let str1 = '(9-2)*5+qty/3-(9-2)*7'
> let str2 = '(qty+4)/2-(9-2)*5+pq/4'
> const pat1 = // add your solution here
> str1.replace() // add your solution here
< '35+qty/3-(9-2)*7'
> str2.replace() // add your solution here
< '(qty+4)/2-35+pq/4'
2) Replace (4)\| with 2 only at the start or end of the given input strings.
> let s1 = '2.3/(4)\\|6 fig 5.3-(4)\\|'
> let s2 = '(4)\\|42 - (4)\\|3'
> let s3 = 'two - (4)\\|\n'
> const pat2 = // add your solution here
> s1.replace() // add your solution here
< '2.3/(4)\\|6 fig 5.3-2'
> s2.replace() // add your solution here
< '242 - (4)\\|3'
> s3.replace() // add your solution here
< 'two - (4)\\|\n'
3) Replace any matching element from the array items with X for given the input strings. Match the elements from items literally. Assume no two elements of items will result in any matching conflict.
> let items = ['a.b', '3+n', 'x\\y\\z', 'qty||price', '{n}']
// add your solution here
> const pat3 = // add your solution here
> '0a.bcd'.replace(pat3, 'X')
< '0Xcd'
> 'E{n}AMPLE'.replace(pat3, 'X')
< 'EXAMPLE'
> '43+n2 ax\\y\\ze'.replace(pat3, 'X')
< '4X2 aXe'
4) Replace the backspace character \b with a single space character for the given input string.
> let ip = '123\b456'
> ip.replace() // add your solution here
< '123 456'
5) Replace all occurrences of \e with e.
> let ip = 'th\\er\\e ar\\e common asp\\ects among th\\e alt\\ernations'
> ip.replace() // add your solution here
< 'there are common aspects among the alternations'
6) Replace any matching item from the array eqns with X for given the string ip. Match the items from eqns literally.
> let ip = '3-(a^b)+2*(a^b)-(a/b)+3'
> let eqns = ['(a^b)', '(a/b)', '(a^b)+2']
// add your solution here
> const pat4 = // add your solution here
> ip.replace(pat4, 'X')
< '3-X*X-X+3'