Unicode
So far in the book, all the examples were meant for strings made up of ASCII characters only. A few years back that would've been sufficient for most of the use cases. These days it is rare to encounter a project that requires only ASCII. This chapter will briefly discuss Unicode matching.
Unicode character sets and the u flag
Similar to escape sequence character sets, the \p{} construct offers various predefined sets to work with Unicode. For negated sets, use \P{}. You'll also need to set the u flag.
// extract all consecutive letters
// \p{L} is an alias for \p{Letter}
> 'fox:αλεπού,eagle:αετός'.match(/\p{L}+/gu)
< ['fox', 'αλεπού', 'eagle', 'αετός']
// extract all consecutive Greek letters
// \p{sc} is an alias for \p{Script}
> 'fox:αλεπού,eagle:αετός'.match(/\p{sc=Greek}+/gu)
< ['αλεπού', 'αετός']
// delete all characters other than letters
> 'φοο12,βτ_4,fig'.replace(/\P{L}+/gu, '')
< 'φοοβτfig'
// extract whole words not surrounded by punctuation marks
> 'tie. ink east;'.match(/(?<!\p{P})\b\w+\b(?!\p{P})/gu)
< ['ink']
See MDN: Unicode character class escape for more details. See also regular-expressions: unicode for an overview of challenges with Unicode matching.
v flag
The v flag is a superset of the u flag. It provides additional \p{} constructs and enables set operations inside character classes. See MDN: unicodeSets for more details. Here are some examples of additional \p{} constructs:
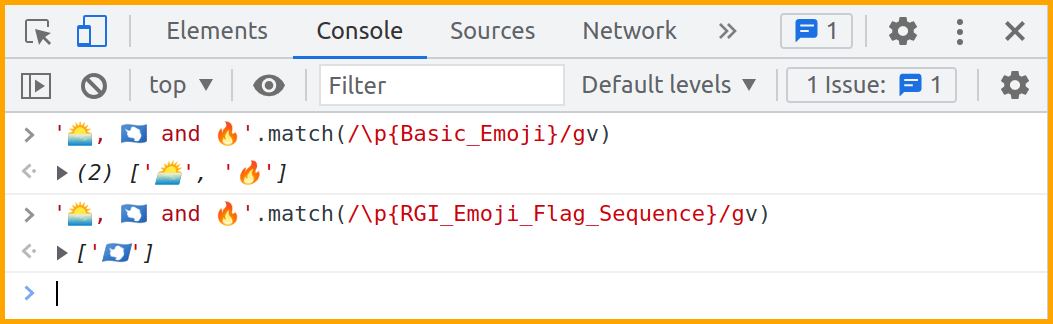
The following set operations are enabled by the v flag inside character classes:
&&intersection--difference
To aid in such definitions, you can use [] in nested fashion. See MDN: v-mode character class for more details. Here are some examples:
// remove all punctuation characters except . ! and ?
> let para = '"Hi", there! How *are* you? All fine here.'
> para.replace(/[\p{P}--[.!?]]+/gv, '')
< 'Hi there! How are you? All fine here.'
// match lowercase alphabets other than vowels
// can also use: /\b[[a-z]--[aeiou]]+\b/gv
> 'tryst glyph pity why'.match(/\b[[a-z]&&[^aeiou]]+\b/gv)
< ['tryst', 'glyph', 'why']
Codepoints
You can also use codepoints (numerical value of a character) inside the \u{} construct to specify Unicode characters. This is similar to how \xhh can be used to specify ASCII characters with two hexadecimal digits.
// to get codepoints in hexadecimal format
> Array.from('fox:αλεπού', c => c.codePointAt().toString(16))
< ['66', '6f', '78', '3a', '3b1', '3bb', '3b5', '3c0', '3bf', '3cd']
// using codepoint to represent a character
> '\u{3b1}'
< 'α'
// character range for lowercase alphabets using \u{}
// note that \u{} will work only with the 'u' or 'v' flags enabled
> 'fox:αλεπού,eagle:αετός'.match(/[\u{61}-\u{7a}]+/gu)
< ['fox', 'eagle']
Cheatsheet and Summary
| Note | Description |
|---|---|
u | flag to enable Unicode matching |
v | superset of u flag, enables additional features |
\p{} | Unicode character sets |
\P{} | negated Unicode character sets |
| see MDN: Unicode character class escape for details | |
\u{} | specify Unicode characters using codepoints |
A comprehensive discussion on regexp usage with Unicode characters is out of scope for this book. Resources like regular-expressions: unicode and Programmers introduction to Unicode are recommended for further study.
Exercises
1) Check if the given input strings are made up of ASCII characters only. Consider the input to be non-empty strings and any character that isn't part of the 7-bit ASCII set should result in false.
> let str1 = '123 × 456'
> let str2 = 'good fοοd'
> let str3 = 'happy learning!'
> const pat1 = // add your solution here
> pat1.test(str1)
< false
> pat1.test(str2)
< false
> pat1.test(str3)
< true
2) Retain only the punctuation characters for the given string.
> let ip = '❨a❩❪1❫❬b❭❮2❯❰c❱❲3❳❴xyz❵⟅123⟆⟦⟧⟨like⟩⟪3.14⟫'
// add your solution here
< '❨❩❪❫❬❭❮❯❰❱❲❳❴❵⟅⟆⟦⟧⟨⟩⟪.⟫'
3) Is the following code snippet showing the correct output?
> 'fox:αλεπού'.match(/\w+/g)
< ['fox']
4) Name the set operations enabled by the v flag.
5) Extract all whole words from the given strings. However, do not match words if they contain any character present in the ignore variable.
> let s1 = 'match after the last new_line character A2'
> let s2 = 'and then you want to test'
> let ignore = 'aty'
> const ign1 = // add your solution here
> s1.match(ign1)
< ['new_line', 'A2']
> s2.match(ign1)
< null
> let ignore = 'esw'
// should be the same solution used above
> const ign2 = // add your solution here
> s1.match(ign2)
< ['match', 'A2']
> s2.match(ign2)
< ['and', 'you', 'to']