Data cleansing
Now that you've seen a basic example with the praw module, you'll start this project by getting the top level comments from two Reddit threads. These threads were used to conduct a poll about favorite speculative fiction written by women. From the raw data so obtained, author names have to be extracted. But the data format isn't always as expected. You'll use regular expressions to explore inconsistencies, remove unwanted characters from the names and ignore entries that couldn't be parsed in the format required.
From wikipedia: Data cleansing:
Data cleansing or data cleaning is the process of identifying and correcting (or removing) corrupt, inaccurate, or irrelevant records from a dataset, table, or database. It involves detecting incomplete, incorrect, or inaccurate parts of the data and then replacing, modifying, or deleting the affected data. Data cleansing can be performed interactively using data wrangling tools, or through batch processing often via scripts or a data quality firewall.
Collecting data
The two poll threads being analyzed for this project are 2019 and 2021. The poll asked users to specify their favorite speculative fictional books written by women, with a maximum of 10 entries. The voting comment was restricted to contain only book titles and authors. Any other discussion had to be placed under those entries as comments.
The below program builds on the example shown earlier. A tuple object stores the voting thread year and the corresponding id values. And then a loop goes over each entry and writes only the top level comments to the respective output files.
# save_top_comments.py
import json
import praw
with open('.secrets/tokens.json') as f:
secrets = json.load(f)
reddit = praw.Reddit(
user_agent=secrets['user_agent'],
client_id=secrets['client_id'],
client_secret=secrets['client_secret'],
)
thread_details = (('2019', 'cib77j'), ('2021', 'm20rd1'))
for year, thread_id in thread_details:
submission = reddit.submission(id=thread_id)
submission.comments.replace_more(limit=None)
op_file = f'top_comments_{year}.txt'
with open(op_file, 'w') as f:
for top_level_comment in submission.comments:
f.write(top_level_comment.body + '\n')
The tokens.json file contains the information passed to the praw.Reddit() method. The data structure is shown below — you'll need to replace the values with your own valid information.
$ cat .secrets/tokens.json
{
"user_agent": "Get Comments by /u/name",
"client_id": "XXX",
"client_secret": "XXX"
}
Data inconsistencies
As mentioned earlier, the poll asked users to specify their favorite speculative fictional books written by women, with a maximum of 10 entries. Users were also instructed to use only one entry per series, but series name or any individual book title can be specified. To analyze this data as intended, you'll have to find a way to collate all entries that fall under the same series. This is out of scope for this project. Instead, only author names will be used for the analysis, which is a significant deviation from the poll's intention.
Counting author names alone makes it easier to code this project, but you'll still come to appreciate why data cleansing is a very important step. Users were asked to write their entries as book title followed by hyphen or the word by and finally the author name. Assuming there is at least one whitespace character before and after the separators, here's a program that displays all the mismatching lines.
import re
file = 'top_comments_2019.txt'
pat = re.compile(r'\s(?:[–-]|by)\s', flags=re.I)
with open(file) as f:
for line in f:
if re.fullmatch(r'\s+', line):
continue
elif not pat.search(line):
print(line, end='')
The re.fullmatch regexp is used to ignore all lines containing only whitespaces. The next regexp checks if hyphen (or em dash) or by surrounded by whitespace characters is present in the line. Case is also ignored when by is matched. Matching the whitespace characters is important because the book titles or author names could contain by or hyphens. While this can still give false matches, the goal is to reduce errors as much as possible, not 100% accuracy. If a line doesn't match this condition, it will be displayed on the screen. About a hundred such lines are found in the top_comments_2019.txt file.
Here's a visual representation of the pat regexp:
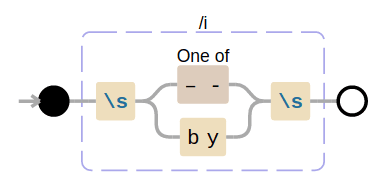
The above railroad diagram for the
r'\s(?:[–-]|by)\s'pattern was created using the debuggex site. You can also visit this regex101 link, which is another popular way to experiment and understand regexp patterns. See my Python re(gex)? ebook if you want to learn more about regular expressions.
And here's a sample of the mismatching lines:
**Wayfarers** \- Becky Chambers
**The Broken Earth** *by N.K. Jemisin*
5. Uprooted- Naomi Novik
Empire of Sand, Tasha Suri
So, some entries used a slightly different markdown style and some used , as the separator. The first two cases can be allowed by optionally matching the \ or * characters. The last two cases will require breaking the whitespace matching rule. For now, this will be allowed so as to proceed further. But in the next section you will see how to apply regexp on a priority basis so that the different rules are applied only for the mismatching lines.
The modified program is shown below. The re.X flag allows you to use literal whitespaces for readability purposes. You can also add comments after the # character if you wish.
# analyze.py
import re
file = 'top_comments_2019.txt'
pat = re.compile(r'''\s(?:[–-]|by)\s
|\s\\[–-]\s
|\s\*by\s
|[,-]\s
''', flags=re.I|re.X)
with open(file) as f:
for line in f:
if re.fullmatch(r'\s+', line):
continue
elif not pat.search(line):
print(line, end='')
After applying this rule, there are less than 50 mismatching lines. Some of them are comments irrelevant to the voting, but some of the entries can still be salvaged by manual modification (for example, entries that have the book title and author names in reversed order). These will be completely ignored for this project, but you can try to correct them if you wish.
Changing the input file to top_comments_2021.txt gives new kind of mismatches. Some of the mismatches are shown below:
The Blue Sword-Robin McKinley
**The Left Hand of Darkness**by Ursula K. Le Guin
Spinning Silver (Naomi Novik)
These can be accommodated by modifying the matching criteria, but since the total count of mismatches is less than 40, they will also be ignored. You can try to improve the code as an exercise. In case you are wondering, total entries are more than 1500 and 3400 for the 2019 and 2021 polls respectively. So, ignoring less than 50 mismatches isn't a substantial loss.
Extracting author names
It is time to extract only the author names and save them for further analysis. The regexp patterns seen in the previous section needs to modified to capture author names at the end of the lines. Also, .* is added at the start so that only the furthest match in the line is extracted. To give priority for the best case matches, the patterns are first stored separately as different elements in a tuple. By looping over these patterns, you can then quit once the earliest match is found.
# extract_author_names.py
import re
ip_files = ('top_comments_2019.txt', 'top_comments_2021.txt')
op_files = ('authors_2019.txt', 'authors_2021.txt')
patterns = (r'.*\s(?:[–-]|by)\s+(.+)',
r'.*\s\\[–-]\s+(.+)',
r'.*\s\*by\s+(.+)',
r'.*[,-]\s+(.+)')
for ip_file, op_file in zip(ip_files, op_files):
with open(ip_file) as ipf, open(op_file, 'w') as opf:
for line in ipf:
if re.fullmatch(r'\s+', line):
continue
for pat in patterns:
if m := re.search(pat, line, flags=re.I):
opf.write(m[1].strip('*\t ') + '\n')
break
If you check the two output files you get, you'll see some entries like shown below. Again, managing these entries is left as an exercise.
Janny Wurts & Raymond E. Feist
Patricia C. Wrede, Caroline Stevermer
Melaine Rawn, Jennifer Roberson, and Kate Elliott
and get to add some stuff I really enjoyed! In no particular order:
but:
Marie Brennan (Memoirs of Lady Trent)
Alice B. Sheldon (as James Tiptree Jr.)
Linda Nagata from The Red trilogy
Novik, Naomi
strip('*\t ') is applied on the captured portion to remove whitespaces at the end of the line, markdown formatting, etc. Without that, you'll get author names likes shown below:
N.K. Jemisin*
ML Wang**
*Mary Robinette Kowal