re introduction
This chapter gives an introduction to the re module. This module is part of the standard library. For some examples, the equivalent normal string method is also shown for comparison. This chapter just focuses on the basics of using functions from the re module. Regular expression features will be covered from the next chapter onwards.
re module documentation
It is always a good idea to know where to find the documentation. The default offering for Python regular expressions is the re standard library module. Visit docs.python: re for information on available methods, syntax, features, examples and more. Here's a quote:
A regular expression (or RE) specifies a set of strings that matches it; the functions in this module let you check if a particular string matches a given regular expression
re.search()
Normally you'd use the in operator to test whether a string is part of another string or not. For regular expressions, use the re.search() function whose argument list is shown below.
re.search(pattern, string, flags=0)
The first argument is the RE pattern you want to test against the input string, which is the second argument. flags is optional, it helps to change the default behavior of RE patterns.
As a good practice, always use raw strings to construct the RE pattern. This will become clearer in later chapters. Here are some examples to get started.
>>> sentence = 'This is a sample string'
# check if 'sentence' contains the given search string
>>> 'is' in sentence
True
>>> 'xyz' in sentence
False
# need to load the re module before use
>>> import re
# check if 'sentence' contains the pattern described by the RE argument
>>> bool(re.search(r'is', sentence))
True
>>> bool(re.search(r'xyz', sentence))
False
Before using the re module, you need to import it. Further example snippets will assume that this module is already loaded. The return value of the re.search() function is a re.Match object when a match is found and None otherwise (note that I treat re as a word, not as r and e separately, hence the use of a instead of an). More details about the re.Match object will be discussed in the Working with matched portions chapter. For presentation purposes, the examples will use the bool() function to show True or False depending on whether the RE pattern matched or not.
Here's an example with the flags optional argument. By default, the pattern will match the input string case sensitively. By using the re.I flag, you can match case insensitively. See the Flags chapter for more details.
>>> sentence = 'This is a sample string'
>>> bool(re.search(r'this', sentence))
False
# re.IGNORECASE (or re.I) is a flag to enable case insensitive matching
>>> bool(re.search(r'this', sentence, flags=re.I))
True
re.search() in conditional expressions
As Python evaluates None as False in boolean context, re.search() can be used directly in conditional expressions. See also docs.python: Truth Value Testing.
>>> sentence = 'This is a sample string'
>>> if re.search(r'ring', sentence):
... print('mission success')
...
mission success
>>> if not re.search(r'xyz', sentence):
... print('mission failed')
...
mission failed
Here are some examples with list comprehensions and generator expressions:
>>> words = ['cat', 'attempt', 'tattle']
>>> [w for w in words if re.search(r'tt', w)]
['attempt', 'tattle']
>>> all(re.search(r'at', w) for w in words)
True
>>> any(re.search(r'stat', w) for w in words)
False
re.sub()
For normal search and replace, you'd use the str.replace() method. For regular expressions, use the re.sub() function, whose argument list is shown below.
re.sub(pattern, repl, string, count=0, flags=0)
The first argument is the RE pattern to match against the input string, which is the third argument. The second argument specifies the string which will replace the portions matched by the RE pattern. count and flags are optional arguments.
>>> greeting = 'Have a nice weekend'
# replace all occurrences of 'e' with 'E'
# same as: greeting.replace('e', 'E')
>>> re.sub(r'e', 'E', greeting)
'HavE a nicE wEEkEnd'
# replace the first two occurrences of 'e' with 'E'
# same as: greeting.replace('e', 'E', count=2)
>>> re.sub(r'e', 'E', greeting, count=2)
'HavE a nicE weekend'
A common mistake, not specific to
re.sub(), is forgetting that strings are immutable in Python.>>> word = 'cater' # this will return a string object, won't modify the 'word' variable >>> re.sub(r'cat', 'wag', word) 'wager' >>> word 'cater' # need to explicitly assign the result if 'word' has to be changed >>> word = re.sub(r'cat', 'wag', word) >>> word 'wager'
Compiling regular expressions
Regular expressions can be compiled using the re.compile() function, which gives back a re.Pattern object.
re.compile(pattern, flags=0)
The top level re module functions are all available as methods for such objects. Compiling a regular expression is useful if the RE has to be used in multiple places or called upon multiple times inside a loop (speed benefit).
By default, Python maintains a small list of recently used RE, so the speed benefit doesn't apply for trivial use cases. See also stackoverflow: Is it worth using re.compile?
>>> pet = re.compile(r'dog')
>>> type(pet)
<class 're.Pattern'>
# note that 'search' is called upon 'pet' which is a 're.Pattern' object
# since 'pet' has the RE information, you only need to pass the input string
>>> bool(pet.search('They bought a dog'))
True
>>> bool(pet.search('A cat crossed their path'))
False
# replace all occurrences of 'dog' with 'cat'
>>> pet.sub('cat', 'They bought a dog')
'They bought a cat'
Some of the methods available for compiled patterns also accept more arguments than those available for the top level functions of the re module. For example, the search() method on a compiled pattern has two optional arguments to specify the start and end index positions. Similar to the range() function and slicing notation, the ending index has to be specified 1 greater than the desired index.
Pattern.search(string[, pos[, endpos]])
Note that there's no flags option as that has to be specified with re.compile().
>>> sentence = 'This is a sample string'
>>> word = re.compile(r'is')
# search for 'is' starting from the 5th character
>>> bool(word.search(sentence, 4))
True
# search for 'is' starting from the 7th character
>>> bool(word.search(sentence, 6))
False
# search for 'is' from the 3rd character to the 4th character
>>> bool(word.search(sentence, 2, 4))
True
bytes
To work with the bytes data type, the RE must be specified as bytes as well. Similar to the str RE, use raw format to construct a bytes RE.
>>> byte_data = b'This is a sample string'
# error message truncated for presentation purposes
>>> re.search(r'is', byte_data)
TypeError: cannot use a string pattern on a bytes-like object
# use rb'..' for constructing bytes pattern
>>> bool(re.search(rb'is', byte_data))
True
>>> bool(re.search(rb'xyz', byte_data))
False
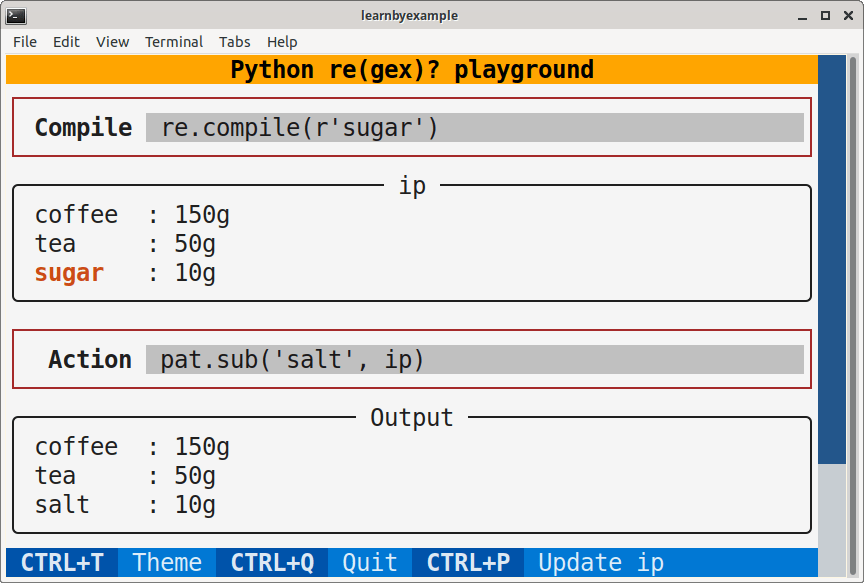
re(gex)? playground
To make it easier to experiment, I wrote an interactive TUI app. See PyRegexPlayground repo for installation instructions and usage guide. A sample screenshot is shown below:
Cheatsheet and Summary
| Note | Description |
|---|---|
| docs.python: re | Python standard module for regular expressions |
re.search() | Check if the given pattern is present anywhere in the input string |
re.search(pattern, string, flags=0) | |
Output is a re.Match object, usable in conditional expressions | |
| raw strings preferred to define RE | |
| Additionally, Python maintains a small cache of recent RE | |
re.sub() | search and replace using RE |
re.sub(pattern, repl, string, count=0, flags=0) | |
re.compile() | Compile a pattern for reuse, output is a re.Pattern object |
re.compile(pattern, flags=0) | |
rb'pat' | Use byte pattern for byte input |
re.IGNORECASE or re.I | flag to ignore case while matching |
This chapter introduced the re module, which is part of the standard library. Functions re.search() and re.sub() were discussed as well as how to compile RE using the re.compile() function. The RE pattern is usually defined using raw strings. For byte input, the pattern has to be of byte type too. Although the re module is good enough for most use cases, there are situations where you need to use the third-party regex module. To avoid mixing up features, a separate chapter is dedicated for the regex module at the end of this book.
The next section has exercises to test your understanding of the concepts introduced in this chapter. Please do solve them before moving on to the next chapter.
Exercises
1) Check whether the given strings contain 0xB0. Display a boolean result as shown below.
>>> line1 = 'start address: 0xA0, func1 address: 0xC0'
>>> line2 = 'end address: 0xFF, func2 address: 0xB0'
>>> bool(re.search(r'', line1)) ##### add your solution here
False
>>> bool(re.search(r'', line2)) ##### add your solution here
True
2) Replace all occurrences of 5 with five for the given string.
>>> ip = 'They ate 5 apples and 5 oranges'
>>> re.sub() ##### add your solution here
'They ate five apples and five oranges'
3) Replace only the first occurrence of 5 with five for the given string.
>>> ip = 'They ate 5 apples and 5 oranges'
>>> re.sub() ##### add your solution here
'They ate five apples and 5 oranges'
4) For the given list, filter all elements that do not contain e.
>>> items = ['goal', 'new', 'user', 'sit', 'eat', 'dinner']
>>> [w for w in items if not re.search()] ##### add your solution here
['goal', 'sit']
5) Replace all occurrences of note irrespective of case with X.
>>> ip = 'This note should not be NoTeD'
>>> re.sub() ##### add your solution here
'This X should not be XD'
6) Check if at is present in the given byte input data.
>>> ip = b'tiger imp goat'
>>> bool(re.search()) ##### add your solution here
True
7) For the given input string, display all lines not containing start irrespective of case.
>>> para = '''good start
... Start working on that
... project you always wanted
... stars are shining brightly
... hi there
... start and try to
... finish the book
... bye'''
>>> pat = re.compile() ##### add your solution here
>>> for line in para.split('\n'):
... if not pat.search(line):
... print(line)
...
project you always wanted
stars are shining brightly
hi there
finish the book
bye
8) For the given list, filter all elements that contain either a or w.
>>> items = ['goal', 'new', 'user', 'sit', 'eat', 'dinner']
##### add your solution here
>>> [w for w in items if re.search() or re.search()]
['goal', 'new', 'eat']
9) For the given list, filter all elements that contain both e and n.
>>> items = ['goal', 'new', 'user', 'sit', 'eat', 'dinner']
##### add your solution here
>>> [w for w in items if re.search() and re.search()]
['new', 'dinner']
10) For the given string, replace 0xA0 with 0x7F and 0xC0 with 0x1F.
>>> ip = 'start address: 0xA0, func1 address: 0xC0'
##### add your solution here
'start address: 0x7F, func1 address: 0x1F'