regex module
The third-party regex module (https://pypi.org/project/regex/) offers advanced features like those found in the Perl language and other regular expression implementations. To install the module from the command line, you can use either of these depending on your usage:
pip install regexin a virtual environmentpython3.13 -m pip install --user regexfor normal environments- you might need to use
pyinstead ofpython3.13on Windows
- you might need to use
By default, the regex module uses VERSION0 which is compatible with the re module. If you want all the features, VERSION1 should be used. For example, set operators is a feature available only if you use VERSION1. You can choose the version to be used in two ways. Setting regex.DEFAULT_VERSION to regex.VERSION0 or regex.VERSION1 is a global option. (?V0) and (?V1) are inline flag options.
The examples in this chapter are presented assuming
VERSION1is enabled.>>> import regex >>> regex.DEFAULT_VERSION = regex.VERSION1 >>> sentence = 'This is a sample string' >>> bool(regex.search(r'is', sentence)) True
Subexpression calls
If backreferences are like variables, then subexpression calls are like functions. Backreferences allow you to reuse the portion matched by the capture group. Subexpression calls allow you to reuse the pattern that was used inside the capture group. You can call subexpressions recursively too, see the Recursive matching section for examples.
Subexpression syntax is (?N) where N is the capture group you want to call. This is applicable only in the RE definition, it wouldn't make sense in replacement sections.
>>> row = 'today,2008-03-24,food,2012-08-12,nice,5632'
# with re module and manually repeating the pattern
>>> re.search(r'\d{4}-\d{2}-\d{2}.*\d{4}-\d{2}-\d{2}', row)[0]
'2008-03-24,food,2012-08-12'
# with regex module and subexpression calling
>>> regex.search(r'(\d{4}-\d{2}-\d{2}).*(?1)', row)[0]
'2008-03-24,food,2012-08-12'
Named capture groups can be called using (?&name) syntax.
>>> row = 'today,2008-03-24,food,2012-08-12,nice,5632'
>>> regex.search(r'(?P<date>\d{4}-\d{2}-\d{2}).*(?&date)', row)[0]
'2008-03-24,food,2012-08-12'
Set the start of matching portion with \K
Some of the positive lookbehind cases can be solved by adding \K as a suffix to the pattern to be asserted. The text consumed until \K won't be part of the matching portion. In other words, \K determines the starting point. The pattern before \K can be variable length too.
# similar to: r'(?<=\b\w)\w*\W*'
# text matched before \K won't be replaced
>>> regex.sub(r'\b\w\K\w*\W*', '', 'sea eat car rat eel tea')
'secret'
# variable length example
>>> s = 'cat scatter cater scat concatenate catastrophic catapult duplicate'
# replace only the third occurrence of 'cat'
>>> regex.sub(r'(cat.*?){2}\Kcat', r'[\g<0>]', s, count=1)
'cat scatter [cat]er scat concatenate catastrophic catapult duplicate'
# replace every third occurrence
>>> regex.sub(r'(cat.*?){2}\Kcat', r'[\g<0>]', s)
'cat scatter [cat]er scat concatenate [cat]astrophic catapult duplicate'
Here's another example that won't work if greedy quantifier is used instead of possessive.
>>> row = '421,cat,2425,42,5,cat,6,6,42,61,6,6,6,6,4'
# lookarounds used to ensure start and end of columns
# possessive quantifier used to ensure partial column is not captured
# if a column has same text as another column, the latter column is deleted
>>> while (op := regex.subn(r'(?<![^,])([^,]++).*\K,\1(?![^,])', '', row))[1]:
... row = op[0]
...
>>> row
'421,cat,2425,42,5,6,61,4'
Variable length lookbehind
The regex module allows variable length lookbehind without needing any special settings.
>>> s = 'pore42 tar3 dare7 care5'
>>> regex.findall(r'(?<!tar|dare)\d+', s)
['42', '5']
>>> regex.findall(r'(?<=\b[pd][a-z]*)\d+', s)
['42', '7']
>>> regex.sub(r'(?<=\A|,)(?=,|\Z)', 'NA', ',1,,,two,3,,,')
'NA,1,NA,NA,two,3,NA,NA,NA'
>>> regex.sub(r'(?<=(cat.*?){2})cat', 'X', 'cat scatter cater scat', count=1)
'cat scatter Xer scat'
>>> bool(regex.search(r'(?<!cat.*)dog', 'fox,cat,dog,parrot'))
False
>>> bool(regex.search(r'(?<!parrot.*)dog', 'fox,cat,dog,parrot'))
True
As lookarounds do not consume characters, don't use variable length lookbehind between two patterns. Use negated groups instead.
# match if 'go' is not there between 'at' and 'par' # lookaround won't work here >>> bool(regex.search(r'at(?<!go.*)par', 'fox,cat,dog,parrot')) False # use negated group instead >>> bool(regex.search(r'at((?!go).)*par', 'fox,cat,dog,parrot')) True
\G anchor
The \G anchor matches the start of the input string, just like the \A anchor. In addition, it will also match at the end of the previous match. This helps you to mark a particular location in the input string and continue from there instead of having the pattern to always check for the specific location. This is best understood with examples.
First, a simple example of using \G without alternations. The goal is to replace every character of the first field with * where whitespace is the field separator.
>>> record = '123-456-7890 Joe (30-40) years'
# simply using \S will replace all the non-whitespace characters
>>> regex.sub(r'\S', '*', record)
'************ *** ******* *****'
# naively adding the \A anchor replaces only the first one
>>> regex.sub(r'\A\S', '*', record)
'*23-456-7890 Joe (30-40) years'
# one workaround is to continuously assert the matching condition
# here, it is non-whitespace characters from the start of the string
>>> regex.sub(r'(?<=\A\S*)\S', '*', record)
'************ Joe (30-40) years'
# \G is a simpler solution for such cases
>>> regex.sub(r'\G\S', '*', record)
'************ Joe (30-40) years'
>>> regex.findall(r'\G\S', record)
['1', '2', '3', '-', '4', '5', '6', '-', '7', '8', '9', '0']
In the above example, \G will first match the start of the string. So, the first character is replaced with * since \S matches the non-whitespace character 1. The ending of 1 will now be considered as the new anchor for \G. The second character will then match because 2 is a non-whitespace character and \G assertion is satisfied due to the previous match. This will continue until the end of the field, which is 0 in the above example. When the next character is considered, \G assertion is still satisfied but \S fails due to the space character. Because the matching failed, \G will not be satisfied when the next character J is considered. So, no more characters can match since this particular example doesn't provide an alternate way for \G to be reactivated.
Here are some more examples of using \G without alternations:
# all digits and optional hyphen combo from the start of string
>>> record = '123-456-7890 Joe (30-40) years'
>>> regex.findall(r'\G\d+-?', record)
['123-', '456-', '7890']
>>> regex.sub(r'\G(\d+)(-?)', r'(\1)\2', record)
'(123)-(456)-(7890) Joe (30-40) years'
# all word characters from the start of string
# only if it is followed by a word character
>>> regex.findall(r'\G\w(?=\w)', 'cat_12 bat_100 kite_42')
['c', 'a', 't', '_', '1']
>>> regex.sub(r'\G\w\K(?=\w)', ':', 'cat_12 bat_100 kite_42')
'c:a:t:_:1:2 bat_100 kite_42'
# all lowercase alphabets or space from the start of string
>>> regex.sub(r'\G[a-z ]', r'(\g<0>)', 'par tar-den hen-food mood')
'(p)(a)(r)( )(t)(a)(r)-den hen-food mood'
Next, using \G as part of alternations so that it can be activated anywhere in the input string. Suppose you need to extract one or more numbers that follow a particular name. Here's one way to solve it:
>>> marks = 'Joe 75 88 Mina 89 85 84 John 90'
# you can also use ' (\d+)' instead of ' \K\d+'
>>> regex.findall(r'(?:Mina|\G) \K\d+', marks)
['89', '85', '84']
>>> regex.findall(r'(?:Joe|\G) \K\d+', marks)
['75', '88']
>>> regex.findall(r'(?:John|\G) \K\d+', marks)
['90']
\G matches the start of the string but the input string doesn't start with a space character. So the regular expression can be satisfied only after the other alternative is matched. Consider the first pattern where Mina is the other alternative. Once that string is found, a space and digit characters will satisfy the rest of the RE. Ending of the match, i.e. Mina 89 in this case, will now be the \G anchoring position. This will allow 85 and 84 to be matched subsequently. After that, J fails the \d pattern and no more matches are possible (as Mina isn't found another time).
In some cases, \G anchoring at the start of the string will cause issues. One workaround is to add a negative lookaround assertion. Here's an example. Goal is to mask the password only for the given name.
>>> passwords = 'Rohit:hunter2 Ram:123456 Ranjit:abcdef'
# the first space separated field is also getting masked here
>>> regex.sub(r'(?:Ram:\K|\G)\S', '*', passwords)
'************* Ram:****** Ranjit:abcdef'
# adding a negative assertion helps
>>> regex.sub(r'(?:Ram:\K|\G(?!\A))\S', '*', passwords)
'Rohit:hunter2 Ram:****** Ranjit:abcdef'
>>> regex.sub(r'(?:Rohit:\K|\G(?!\A))\S', '*', passwords)
'Rohit:******* Ram:123456 Ranjit:abcdef'
Recursive matching
The subexpression call special group was introduced as analogous to function calls. And similar to functions, it does support recursion. Useful to match nested patterns, which is usually not recommended to be done with regular expressions. Indeed, you should use a proper parser library for file formats like html, xml, json, csv, etc. But for some cases, a parser might not be available and using RE might be simpler than writing one from scratch.
First up, a RE to match a set of parentheses that is not nested (termed as level-one RE for reference).
>>> eqn0 = 'a + (b * c) - (d / e)'
>>> regex.findall(r'\([^()]++\)', eqn0)
['(b * c)', '(d / e)']
>>> eqn1 = '((f+x)^y-42)*((3-g)^z+2)'
>>> regex.findall(r'\([^()]++\)', eqn1)
['(f+x)', '(3-g)']
Next, matching a set of parentheses which may optionally contain any number of non-nested sets of parentheses (termed as level-two RE for reference). Visual railroad diagram shows the recursive nature of this RE (generated via debuggex):
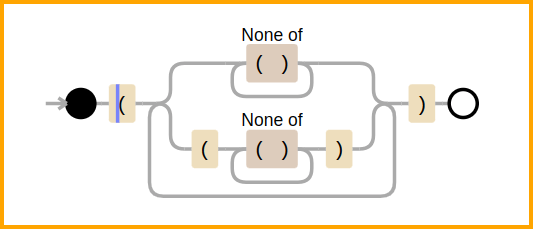
>>> eqn1 = '((f+x)^y-42)*((3-g)^z+2)'
# note the use of non-capturing group
>>> regex.findall(r'\((?:[^()]++|\([^()]++\))++\)', eqn1)
['((f+x)^y-42)', '((3-g)^z+2)']
>>> eqn2 = 'a + (b) + ((c)) + (((d)))'
>>> regex.findall(r'\((?:[^()]++|\([^()]++\))++\)', eqn2)
['(b)', '((c))', '((d))']
That looks very cryptic. Better to use the regex.X flag for clarity as well as for comparing against the recursive version. Breaking down the RE, you can see that ( and ) have to be matched literally. Inside that, valid string is made up of either non-parentheses characters or a non-nested parentheses sequence (level-one RE).
>>> lvl2 = regex.compile(r'''
... \( # literal (
... (?: # start of non-capturing group
... [^()]++ # non-parentheses characters
... | # OR
... \([^()]++\) # level-one RE
... )++ # end of non-capturing group, 1 or more times
... \) # literal )
... ''', flags=regex.X)
>>> lvl2.findall(eqn1)
['((f+x)^y-42)', '((3-g)^z+2)']
>>> lvl2.findall(eqn2)
['(b)', '((c))', '((d))']
To recursively match any number of nested sets of parentheses, use a capture group and call it within the capture group itself. Since entire RE needs to be called here, you can use the default zeroth capture group (this also helps to avoid having to use finditer()). Comparing with the level-two RE, the only change is that (?0) is used instead of the level-one RE in the second alternation.
>>> lvln = regex.compile(r'''
... \( # literal (
... (?: # start of non-capturing group
... [^()]++ # non-parentheses characters
... | # OR
... (?0) # recursive call
... )++ # end of non-capturing group, 1 or more times
... \) # literal )
... ''', flags=regex.X)
>>> lvln.findall(eqn0)
['(b * c)', '(d / e)']
>>> lvln.findall(eqn1)
['((f+x)^y-42)', '((3-g)^z+2)']
>>> lvln.findall(eqn2)
['(b)', '((c))', '(((d)))']
>>> eqn3 = '(3+a) * ((r-2)*(t+2)/6) + 42 * (a(b(c(d(e)))))'
>>> lvln.findall(eqn3)
['(3+a)', '((r-2)*(t+2)/6)', '(a(b(c(d(e)))))']
Named character sets
A named character set is defined by a name enclosed between [: and :] and has to be used within a character class [], along with any other characters as needed. Using [:^ instead of [: will negate the named character set. See regular-expressions: POSIX Bracket for a complete list, and refer to pypi: regex for notes on Unicode.
# similar to: r'\d+' or r'[0-9]+'
>>> regex.split(r'[[:digit:]]+', 'Sample123string42with777numbers')
['Sample', 'string', 'with', 'numbers']
# similar to: r'[a-zA-Z]+'
>>> regex.sub(r'[[:alpha:]]+', ':', 'Sample123string42with777numbers')
':123:42:777:'
# similar to: r'[\w\s]+'
>>> regex.findall(r'[[:word:][:space:]]+', 'tea sea-pit sit-lean\tbean')
['tea sea', 'pit sit', 'lean\tbean']
# similar to: r'\S+'
>>> regex.findall(r'[[:^space:]]+', 'tea sea-pit sit-lean\tbean')
['tea', 'sea-pit', 'sit-lean', 'bean']
# words not surrounded by punctuation characters
>>> regex.findall(r'(?<![[:punct:]])\b\w+\b(?![[:punct:]])', 'tie. ink eat;')
['ink']
Set operations
Set operators can be used inside character class between sets. Mostly used to get intersection or difference between two sets, where one/both of them is a character range or a predefined character set. To aid in such definitions, you can use [] in nested fashion. The four operators, in increasing order of precedence, are:
||union~~symmetric difference&&intersection--difference
As mentioned at the start of this chapter, VERSION1 is needed for this feature to work. Here are some examples:
# [^aeiou] will match any non-vowel character
# which means space is also a valid character to be matched
>>> regex.findall(r'\b[^aeiou]+\b', 'tryst glyph pity why')
['tryst glyph ', ' why']
# intersection or difference can be used here
# to get a positive definition of characters to match
# same as: r'\b[a-z--[aeiou]]+\b'
>>> regex.findall(r'\b[a-z&&[^aeiou]]+\b', 'tryst glyph pity why')
['tryst', 'glyph', 'why']
# [[a-l]~~[g-z]] is same as [a-fm-z]
>>> regex.findall(r'\b[[a-l]~~[g-z]]+\b', 'gets eat top sigh')
['eat', 'top']
# remove all punctuation characters except . ! and ?
>>> para = '"Hi", there! How *are* you? All fine here.'
>>> regex.sub(r'[[:punct:]--[.!?]]+', '', para)
'Hi there! How are you? All fine here.'
remodule in future.
Unicode character sets
Similar to named character classes and escape sequence character sets, the regex module also supports \p{} construct that offers various predefined sets to work with Unicode strings. See regular-expressions: Unicode for more details.
# extract all consecutive letters
# \p{L} is an alias for \p{Letter}
>>> regex.findall(r'\p{L}+', 'fox:αλεπού,eagle:αετός')
['fox', 'αλεπού', 'eagle', 'αετός']
# extract all consecutive Greek letters
>>> regex.findall(r'\p{Greek}+', 'fox:αλεπού,eagle:αετός')
['αλεπού', 'αετός']
# extract all words
>>> regex.findall(r'\p{Word}+', 'φοο12,βτ_4;cat')
['φοο12', 'βτ_4', 'cat']
Use the uppercase format \P{} or use ^ immediately after \p{ for negation:
# delete all characters other than letters
# \p{^L} can also be used
>>> regex.sub(r'\P{L}+', '', 'φοο12,βτ_4;cat')
'φοοβτcat'
Skipping matches
Sometimes, you want to change or extract all matches except particular portions. Usually, there are common characteristics between the two types of matches that makes it hard or impossible to define a RE only for the required matches. For example, changing field values unless it is a particular name, or perhaps don't touch double quoted values and so on. To use the skipping feature, define the matches to be ignored suffixed by (*SKIP)(*FAIL) and then put the required matches as part of an alternation list. (*F) can also be used instead of (*FAIL).
# change whole words other than 'imp' or 'ant'
>>> words = 'tiger imp goat eagle ant important imp2 Cat'
>>> regex.sub(r'\b(?:imp|ant)\b(*SKIP)(*F)|\w++', r'(\g<0>)', words)
'(tiger) imp (goat) (eagle) ant (important) (imp2) (Cat)'
# change all commas other than those inside double quotes
>>> row = '1,"cat,12",nice,two,"dog,5"'
>>> regex.sub(r'"[^"]++"(*SKIP)(*F)|,', '|', row)
'1|"cat,12"|nice|two|"dog,5"'
\m and \M word anchors
\b matches both the start and end of words. In some cases, that can cause issues. You can use the \m and \M anchors to match only the start and end of words respectively.
>>> regex.sub(r'\b', ':', 'hi log_42 12b')
':hi: :log_42: :12b:'
>>> regex.sub(r'\m', ':', 'hi log_42 12b')
':hi :log_42 :12b'
>>> regex.sub(r'\M', ':', 'hi log_42 12b')
'hi: log_42: 12b:'
>>> regex.sub(r'\b..\b', r'[\g<0>]', 'I have 12, he has 2!')
'[I ]have [12][, ][he] has[ 2]!'
>>> regex.sub(r'\m..\M', r'[\g<0>]', 'I have 12, he has 2!')
'I have [12], [he] has 2!'
Overlapped matches
You can use overlapped=True to get overlapped matches.
>>> words = 'on vast ever road lane at peak'
>>> regex.findall(r'\b\w+ \w+\b', words)
['on vast', 'ever road', 'lane at']
>>> regex.findall(r'\b\w+ \w+\b', words, overlapped=True)
['on vast', 'vast ever', 'ever road', 'road lane', 'lane at', 'at peak']
>>> regex.findall(r'\w{2}', 'apple', overlapped=True)
['ap', 'pp', 'pl', 'le']
regex.REVERSE flag
The regex.R or regex.REVERSE flag will result in right-to-left processing instead of the usual left-to-right order.
>>> words = 'par spare lion part cool'
# replaces the first match
>>> regex.sub(r'par', 'X', words, count=1)
'X spare lion part cool'
# replaces the last match
>>> regex.sub(r'par', 'X', words, count=1, flags=regex.R)
'par spare lion Xt cool'
# get matches in reversed order
>>> regex.findall(r'(?r)\w+', words)
['cool', 'part', 'lion', 'spare', 'par']
# alternate to atomic grouping example seen earlier
>>> ip = 'fig::mango::pineapple::guava::apples::orange'
>>> regex.search(r'(?r)::.*?::apple', ip)[0]
'::guava::apple'
# this won't be possible with just atomic grouping
>>> ip = 'and this book is good and those are okay and that movie is bad'
>>> regex.search(r'(?r)th.*?\bis bad', ip)[0]
'that movie is bad'
\X vs dot metacharacter
Some characters have more than one codepoint. These are handled in Unicode with grapheme clusters. The dot metacharacter will only match one codepoint at a time. You can use \X to match any character even if it has multiple codepoints. Another difference from dot metacharacter is that \X will always match newline characters too.
>>> [c.encode('unicode_escape') for c in 'g̈']
[b'g', b'\\u0308']
>>> regex.sub(r'a.e', 'o', 'cag̈ed')
'cag̈ed'
>>> regex.sub(r'a..e', 'o', 'cag̈ed')
'cod'
>>> regex.sub(r'a\Xe', 'o', 'cag̈ed')
'cod'
# \X will always match newline characters, DOTALL flag isn't needed
>>> regex.sub(r'e\Xa', 'i', 'nice he\nat')
'nice hit'
Cheatsheet and Summary
| Note | Description |
|---|---|
| pypi: regex | third-party module, has many advanced features |
default is VERSION0 which is compatible with the re module | |
(?V1) | inline flag to enable version 1 for regex module |
regex.DEFAULT_VERSION=regex.VERSION1 can also be used | |
(?V0) or regex.VERSION0 to get back default version | |
(?N) | subexpression call for the Nth capture group |
(?&name) | subexpression call for named capture groups |
| subexpression call is similar to functions, recursion also possible | |
r'\((?:[^()]++|(?0))++\)' matches nested sets of parentheses | |
pat\K | pat won't be part of the matching portion |
\K can be used for some of the positive lookbehind cases | |
regex module also supports variable length lookbehinds | |
\G | restricts matching from the start of string like \A |
| continues matching from the end of previous match as the new anchor | |
regex.findall(r'\G\d+-?', '12-34 42') gives ['12-', '34'] | |
findall(r'(?:M|\G) \K\d+', 'J 75 M 8 5') gives ['8', '5'] | |
[[:digit:]] | named character set for \d |
[[:^digit:]] | to indicate \D |
| See regular-expressions: POSIX Bracket for a complete list | |
| set operations | feature for character classes, nested [] allowed |
|| union, ~~ symmetric difference | |
&& intersection, -- difference | |
[[:punct:]--[.!?]] punctuation except . ! and ? | |
\p{} | Unicode character sets |
| see regular-expressions: Unicode for details | |
\P{L} or \p{^L} | match characters other than the \p{L} set |
pat(*SKIP)(*F) | ignore text matched by pat |
"[^"]++"(*SKIP)(*F)|, will match , but not inside | |
| double quoted pairs | |
\m and \M | anchors for the start and end of word respectively |
overlapped | set as True to match overlapping portions |
regex.R | REVERSE flag to match from right-to-left |
\X | matches any character even if it has multiple codepoints |
\X will also match newline characters by default | |
whereas . requires the DOTALL flag to match newline characters |
There are plenty of features provided by the regex module. Some of them have not been covered in this chapter — for example, fuzzy matching and splititer(). See pypi: regex for details and examples. For those familiar with Perl style regular expressions, this module offers easier transition compared to the builtin re module.
Exercises
1) List the two regex module constants that affect the compatibility with the re module. Also specify their corresponding inline flags.
2) Replace sequences made up of words separated by : or . by the first word of the sequence and the separator. Such sequences will end when : or . is not followed by a word character.
>>> ip = 'wow:Good:2_two.five: hi-2 bye kite.777:water.'
##### add your solution here
'wow: hi-2 bye kite.'
3) The given list of strings has fields separated by the : character. Delete : and the last field if there is a digit character anywhere before the last field.
>>> items = ['42:cat', 'twelve:a2b', 'we:be:he:0:a:b:bother', 'fig-42:cherry:']
##### add your solution here
['42', 'twelve:a2b', 'we:be:he:0:a:b', 'fig-42:cherry']
4) Extract all whole words unless they are preceded by : or <=> or ---- or #.
>>> ip = '::very--at<=>row|in.a_b#b2c=>lion----east'
##### add your solution here
['at', 'in', 'a_b', 'lion']
5) The given input string has fields separated by the : character. Extract field contents only if the previous field contains a digit character.
>>> ip = 'vast:a2b2:ride:in:awe:b2b:3list:end'
##### add your solution here
['ride', '3list', 'end']
6) The given input strings have fields separated by the : character. Assume that each string has a minimum of two fields and cannot have empty fields. Extract all fields, but stop if a field with a digit character is found.
>>> row1 = 'vast:a2b2:ride:in:awe:b2b:3list:end'
>>> row2 = 'um:no:low:3e:s4w:seer'
>>> row3 = 'oh100:apple:banana:fig'
>>> row4 = 'Dragon:Unicorn:Wizard-Healer'
>>> pat = regex.compile() ##### add your solution here
>>> pat.findall(row1)
['vast']
>>> pat.findall(row2)
['um', 'no', 'low']
>>> pat.findall(row3)
[]
>>> pat.findall(row4)
['Dragon', 'Unicorn', 'Wizard-Healer']
7) For the given input strings, extract if followed by any number of nested parentheses. Assume that there will be only one such pattern per input string.
>>> ip1 = 'for (((i*3)+2)/6) if(3-(k*3+4)/12-(r+2/3)) while()'
>>> ip2 = 'if+while if(a(b)c(d(e(f)1)2)3) for(i=1)'
>>> pat = regex.compile() ##### add your solution here
>>> pat.search(ip1)[0]
'if(3-(k*3+4)/12-(r+2/3))'
>>> pat.search(ip2)[0]
'if(a(b)c(d(e(f)1)2)3)'
8) Read about the POSIX flag from https://pypi.org/project/regex/. Is the following code snippet showing the correct output?
>>> words = 'plink incoming tint winter in caution sentient'
>>> change = regex.compile(r'int|in|ion|ing|inco|inter|ink', flags=regex.POSIX)
>>> change.sub('X', words)
'plX XmX tX wX X cautX sentient'
9) Extract all whole words for the given input strings. However, based on the user input ignore, do not match words if they contain any character present in the ignore variable.
>>> s1 = 'match after the last new_line character A2'
>>> s2 = 'and then you want to test'
>>> ignore = 'aty'
>>> pat = regex.compile() ##### add your solution here
>>> pat.findall(s1)
['new_line', 'A2']
>>> pat.findall(s2)
[]
>>> ignore = 'esw'
# should be the same solution used above
>>> pat = regex.compile() ##### add your solution here
>>> pat.findall(s1)
['match', 'A2']
>>> pat.findall(s2)
['and', 'you', 'to']
10) Retain only the punctuation characters for the given strings (generated from codepoints). Consider the characters defined by the Unicode set \p{P} as punctuations for this exercise.
>>> s1 = ''.join(chr(c) for c in range(0, 0x80))
>>> s2 = ''.join(chr(c) for c in range(0x80, 0x100))
>>> s3 = ''.join(chr(c) for c in range(0x2600, 0x27ec))
>>> pat = regex.compile() ##### add your solution here
>>> pat.sub('', s1)
'!"#%&\'()*,-./:;?@[\\]_{}'
>>> pat.sub('', s2)
'¡§«¶·»¿'
>>> pat.sub('', s3)
'❨❩❪❫❬❭❮❯❰❱❲❳❴❵⟅⟆⟦⟧⟨⟩⟪⟫'
11) For the given markdown file, replace all occurrences of the string python (irrespective of case) with the string Python. However, any match within code blocks that starts with the whole line ```python and ends with the whole line ``` shouldn't be replaced. Consider the input file to be small enough to fit memory requirements.
Refer to the exercises folder for the files sample.md and expected.md required to solve this exercise.
>>> ip_str = open('sample.md', 'r').read()
>>> pat = regex.compile() ##### add your solution here
>>> with open('sample_mod.md', 'w') as op_file:
... ##### add your solution here
...
305
>>> assert open('sample_mod.md').read() == open('expected.md').read()
12) For the given input strings, construct a word that is made up of the last characters of all the words in the input. Use the last character of the last word as the first character, last character of the last but one word as the second character and so on.
>>> s1 = 'knack tic pi roar what'
>>> s2 = ':42;rod;t2t2;car--'
>>> pat = regex.compile() ##### add your solution here
##### add your solution here for s1
'trick'
##### add your solution here for s2
'r2d2'
13) Replicate str.rpartition() functionality with regular expressions. Split into three parts based on the last match of sequences of digits, which is 777 and 12 for the given input strings.
>>> s1 = 'Sample123string42with777numbers'
>>> s2 = '12apples'
>>> pat = regex.compile() ##### add your solution here
>>> pat.split(s1)
['Sample123string42with', '777', 'numbers']
>>> pat.split(s2)
['', '12', 'apples']
14) Read about fuzzy matching from https://pypi.org/project/regex/. For the given input strings, return True if they are exactly the same as cat or there is exactly one character difference. Ignore case differences. For example, Ca2 should give True. act will be False even though the characters are same because position should also be considered.
>>> pat = regex.compile() ##### add your solution here
>>> bool(pat.fullmatch('CaT'))
True
>>> bool(pat.fullmatch('scat'))
False
>>> bool(pat.fullmatch('ca.'))
True
>>> bool(pat.fullmatch('ca#'))
True
>>> bool(pat.fullmatch('c#t'))
True
>>> bool(pat.fullmatch('at'))
False
>>> bool(pat.fullmatch('act'))
False
>>> bool(pat.fullmatch('2a1'))
False
15) The given input strings have fields separated by the : character. Extract all fields only after a field containing a digit character is found. Assume that each string has a minimum of two fields and cannot have empty fields.
>>> row1 = 'vast:a2b2:ride:in:awe:b2b:3list:end'
>>> row2 = 'um:no:low:3e:s4w:seer'
>>> row3 = 'oh100:apple:banana:fig'
>>> row4 = 'Dragon:Unicorn:Wizard-Healer'
>>> pat = regex.compile() ##### add your solution here
>>> pat.findall(row1)
['ride', 'in', 'awe', 'b2b', '3list', 'end']
>>> pat.findall(row2)
['s4w', 'seer']
>>> pat.findall(row3)
['apple', 'banana', 'fig']
>>> pat.findall(row4)
[]