Python Regex Surprises
In this post, you'll find a few regular expression examples that might surprise you. Some are Python specific and some are applicable to other regex flavors as well. To make it more interesting, these are framed as questions for you to ponder upon. Answers are hidden by default.

Poster created using Canva
 If you are not familiar with regular expressions, check out my Understanding Python re(gex)? ebook.
If you are not familiar with regular expressions, check out my Understanding Python re(gex)? ebook.
$ vs \Z🔗
Are the $ and \Z anchors equivalent?Click to view answer
$ can match both the end of string and just before \n if it is the last character. \Z will only match the end of string.>>> greeting = 'hi there\nhave a nice day\n'
>>> bool(re.search(r'day$', greeting))
True
>>> bool(re.search(r'day\n$', greeting))
True
>>> bool(re.search(r'day\Z', greeting))
False
>>> bool(re.search(r'day\n\Z', greeting))
True
Slicing vs start and end arguments🔗
Did you know that you can specify start and end index arguments for compiled methods?
Pattern.search(string[, pos[, endpos]])
Now, here's a conundrum:
>>> word_pat = re.compile(r'\Aat')
>>> bool(word_pat.search('cater'[1:]))
True
# what will be the output?
>>> bool(word_pat.search('cater', 1))
Click to view answer
Specifying a greater than0 start index when using \A is always going to return False. This is because, as far as the search() method is concerned, only the search space has been narrowed — the anchor positions haven't changed. When slicing is used, you are creating an entirely new string object with new anchor positions.Do ^ and $ match after the last newline?🔗
When you use the Yes, they will both match after the last newline character.re.MULTILINE flag, the ^ and $ anchors will match at the start and end of every input line. Question is, will they also match after a newline character at the end of the input?Click to view answer
>>> print(re.sub(r'(?m)^', 'apple ', '1\n2\n'))
apple 1
apple 2
apple
>>> print(re.sub(r'(?m)$', ' banana', '1\n2\n'))
1 banana
2 banana
banana
Word boundary vs lookarounds🔗
False! In contrast, the negative lookarounds version ensures that there are no word characters around any two characters. Also, such assertions will always be satisfied at the start of string and the end of string respectively. But \b..\b is same as (?<!\w)..(?!\w) — True or False?Click to view answer
\b matches both the start and end of word locations. In the below example, \b..\b doesn't necessarily mean that the first \b will match only the start of word location and the second \b will match only the end of word location. They can be any combination! For example, I followed by space in the input string here is using the start of word location for both the conditions. Similarly, space followed by 2 is using the end of word location for both the conditions.\b depends on the presence of word characters. For example, ! at the end of the input string here matches the lookaround assertion but not word boundary.>>> ip = 'I have 12, he has 2!'
>>> re.sub(r'\b..\b', '{\g<0>}', ip)
'{I }have {12}{, }{he} has{ 2}!'
>>> re.sub(r'(?<!\w)..(?!\w)', '{\g<0>}', ip)
'I have {12}, {he} has {2!}'
Undefined escape sequences🔗
If you use undefined escape sequences like Python raises an exception for escape sequences that are not defined. Apart from sequences defined for character sets (for example \e, will you get an error or will it match the unescaped character (e for this example`)?Click to view answer
\d, \w, \s, etc), these are allowed: \a \b \f \n \N \r \t \u \U \v \x \\ where \b means backspace only in character classes. Also, \u and \U are valid only in Unicode patterns.>>> bool(re.search(r'\t', 'cat\tdog'))
True
>>> bool(re.search(r'\c', 'cat\tdog'))
re.error: bad escape \c at position 0
Using octal and hexadecimal escapes in the replacement section🔗
In string literals, you can use octal, hexadecimal and unicode escapes to represent a character. For example, Only octal escapes are allowed inside raw strings in the replacement section. If you are otherwise not using the I feel like it would have been rather better if octal escapes were also not allowed. That would have allowed us to use '\174' is same as using '|'. Do you know which of these escapes you can use inside raw strings in the replacement section of the sub() function?Click to view answer
\ character, then using normal strings in the replacement section is preferred as it will also allow hexadecimal and unicode escapes.>>> re.sub(r',', r'\x7c', '1,2')
re.error: bad escape \x at position 0
>>> re.sub(r',', r'\174', '1,2')
'1|2'
>>> re.sub(r',', '\x7c', '1,2')
'1|2'
\0 instead of \g<0> for backreferencing the entire matched portion in the replacement section.
Using escape sequences for metacharacters🔗
In the search section, if you use an escape (for example, \x7c to represent the | character), will it behave as the alternation metacharacter or match it literally?
>>> re.sub(r'2|3', '5', '12|30')
'15|50'
# what will be the output?
>>> re.sub(r'2\x7c3', '5', '12|30')
Click to view answer
The output will be '150' since escapes will be treated literally.
Empty matches🔗
You are likely to have come across this before:
# what will be the output?
>>> re.sub(r'[^,]*', r'{\g<0>}', ',cat,tiger')
Click to view answer
See also Zero-Length Matches.
# there is an extra empty string match at the end of matches
>>> re.sub(r'[^,]*', r'{\g<0>}', ',cat,tiger')
'{},{cat}{},{tiger}{}'
>>> re.sub(r'[^,]*+', r'{\g<0>}', ',cat,tiger')
'{},{cat}{},{tiger}{}'
# use lookarounds as a workaround
>>> re.sub(r'(?<![^,])[^,]*', r'{\g<0>}', ',cat,tiger')
'{},{cat},{tiger}'
Can quantifiers be grouped out?🔗
Similar to Railroad diagram created using debuggex.com False. Because a(b+c)d = abd+acd in maths, you get a(b|c)d = abd|acd in regular expressions. (a*|b*) is same as (a|b)* — True or False?Click to view answer
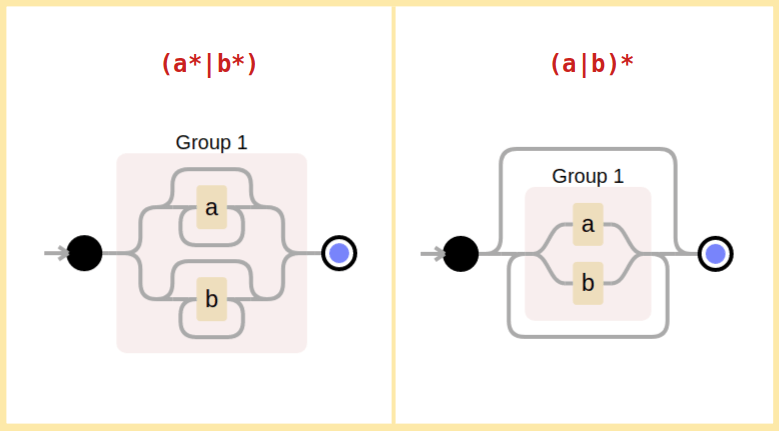
(a*|b*) will match only sequences like a, aaa, bb, bbbbbbbb. But (a|b)* can match mixed sequences like ababbba too.
Portion captured by a quantified group🔗
This should be another familiar regex gotcha:
# what will be the output?
>>> re.sub(r'\A([^,]+,){3}([^,]+)', r'\1(\2)', '1,2,3,4,5,6,7')
Click to view answer
Referring to the text matched by a capture group with a quantifier will give only the last match, not the entire match. You'll need an outer capture group to get the entire matched portion.
>>> re.sub(r'\A([^,]+,){3}([^,]+)', r'\1(\2)', '1,2,3,4,5,6,7')
'3,(4),5,6,7'
>>> re.sub(r'\A((?:[^,]+,){3})([^,]+)', r'\1(\2)', '1,2,3,4,5,6,7')
'1,2,3,(4),5,6,7'
Character combinations🔗
False. \b[a-z](on|no)[a-z]\b is same as \b[a-z][on]{2}[a-z]\b — True or False?Click to view answer
[on]{2} will also match oo and nn.>>> words = 'known mood know pony inns'
>>> re.findall(r'\b[a-z](?:on|no)[a-z]\b', words)
['know', 'pony']
>>> re.findall(r'\b[a-z][on]{2}[a-z]\b', words)
['mood', 'know', 'pony', 'inns']
Greedy vs Possessive🔗
Suppose you want to match integer numbers greater than or equal to 100 where these numbers can optionally have leading zeros. Will the below code work? If not, what would you use instead?
>>> numbers = '42 314 001 12 00984'
# will this work?
>>> re.findall(r'0*\d{3,}', numbers)
Click to view answer
No. You can either modify the pattern such that 0* won't interfere or use possessive quantifiers to prevent backtracking.
>>> numbers = '42 314 001 12 00984'
# this solution fails because 0* and \d{3,} can both match leading zeros
# and greedy quantifiers will give up characters to help overall RE succeed
>>> re.findall(r'0*\d{3,}', numbers)
['314', '001', '00984']
# 0*+ is possessive, will never give back leading zeros
>>> re.findall(r'0*+\d{3,}', numbers)
['314', '00984']
# workaround if possessive isn't supported
>>> re.findall(r'0*[1-9]\d{2,}', numbers)
['314', '00984']
See my blog post on possessive quantifiers and atomic grouping for more examples, details about catastrophic backtracking and so on.
Optional flags argument🔗
Will the sub() function in the code sample below match case insensitively or not?
>>> re.findall(r'key', 'KEY portkey oKey Keyed', re.I)
['KEY', 'key', 'Key', 'Key']
# what will be the output?
>>> re.sub(r'key', r'(\g<0>)', 'KEY portkey oKey Keyed', re.I)
Click to view answer
You should always pass flags as a keyword argument. Using it as positional argument leads to a common mistake between re.findall() and re.sub() functions due to difference in their placement.
re.findall(pattern, string, flags=0)
re.sub(pattern, repl, string, count=0, flags=0)
>>> +re.I
2
# works because flags is the only optional argument for findall
>>> re.findall(r'key', 'KEY portkey oKey Keyed', re.I)
['KEY', 'key', 'Key', 'Key']
# wrong usage, but no error because re.I has a value of 2
# so, this is same as specifying count=2
>>> re.sub(r'key', r'(\g<0>)', 'KEY portkey oKey Keyed', re.I)
'KEY port(key) oKey Keyed'
# correct use of keyword argument
>>> re.sub(r'key', r'(\g<0>)', 'KEY portkey oKey Keyed', flags=re.I)
'(KEY) port(key) o(Key) (Key)ed'
# alternatively, you can use inline flags to avoid this problem altogether
>>> re.sub(r'(?i)key', r'(\g<0>)', 'KEY portkey oKey Keyed')
'(KEY) port(key) o(Key) (Key)ed'
re vs regex module flags🔗
The third-party When using the flags argument with the Again, you can use inline flags to avoid such issues.regex module is handy for advanced features like subexpression calls, skipping matches and so on. Can you use re module flag constants with the regex module?Click to view answer
regex module, the constants should also be used from the regex module.>>> +re.A
256
>>> +regex.A
128
Understanding Python re(gex)? book🔗
Visit my GitHub repo Understanding Python re(gex)? for details about the book I wrote on Python regular expressions. The ebook uses plenty of examples to explain the concepts from the very beginning and step by step introduces more advanced concepts. The book also covers the third-party module regex.